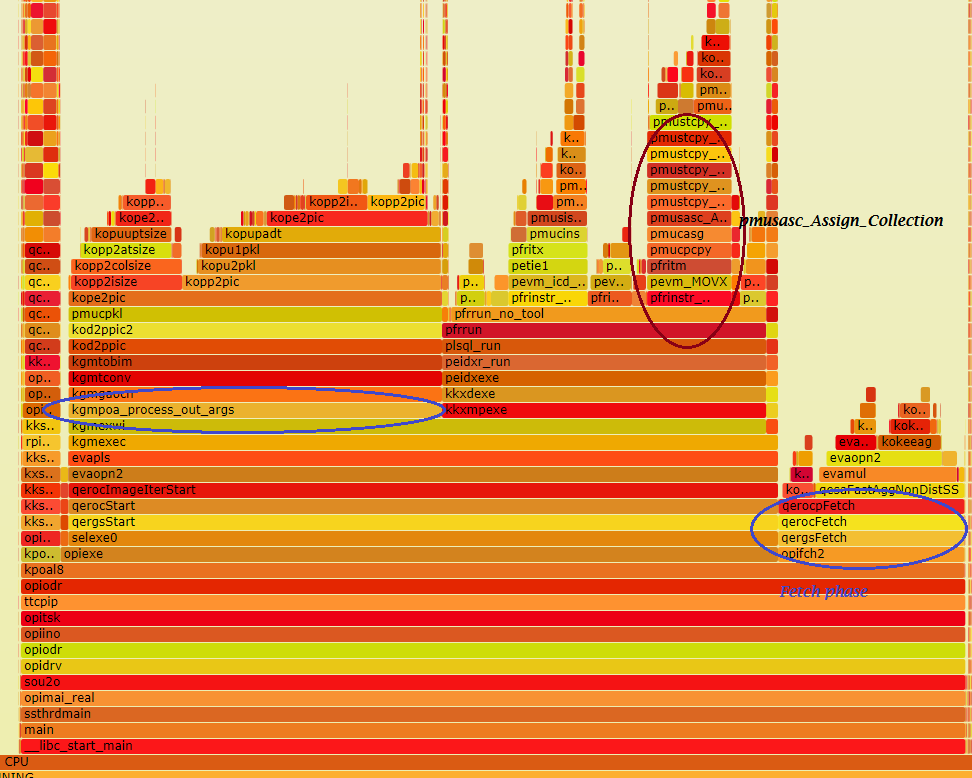
Script for SQL*Plus: https://github.com/xtender/xt_scripts/blob/master/tops/top_seg_by_size.sql
with
seg as (
select
owner,segment_name
,segment_type
,tablespace_name
,sum(blocks) blocks
,sum(bytes) bytes
from dba_segments s
where segment_type not in (
'TYPE2 UNDO'
,'ROLLBACK'
,'SYSTEM STATISTICS'
)
and segment_name not like 'BIN$%' --not in recyclebin
and owner like '&owner_mask' -- you can specify schema here
group by owner,segment_name,segment_type,tablespace_name
)
,segs as (
select
owner,segment_name
,case when segment_name like 'DR$%$%' then 'CTX INDEX' else segment_type end segment_type
,tablespace_name
,case
when segment_name like 'DR$%$%'
then (select table_owner||'.'||table_name from dba_indexes i where i.owner=s.owner and i.index_name = substr(segment_name,4,length(segment_name)-5))
when segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION')
then owner||'.'||segment_name
when segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION')
then (select i.table_owner||'.'||i.table_name from dba_indexes i where i.owner=s.owner and i.index_name=s.segment_name)
when segment_type in ('LOBSEGMENT','LOB PARTITION','LOB SUBPARTITION')
then (select l.owner||'.'||l.TABLE_NAME from dba_lobs l where l.segment_name = s.segment_name and l.owner = s.owner)
when segment_type = 'LOBINDEX'
then (select l.owner||'.'||l.TABLE_NAME from dba_lobs l where l.index_name = s.segment_name and l.owner = s.owner)
when segment_type = 'NESTED TABLE'
then (select nt.owner||'.'||nt.parent_table_name from dba_nested_tables nt where nt.owner=s.owner and nt.table_name=s.segment_name)
when segment_type = 'CLUSTER'
then (select min(owner||'.'||table_name) from dba_tables t where t.owner=s.owner and t.cluster_name=s.segment_name and rownum=1)
end table_name
,blocks
,bytes
from seg s
)
,so as (
select
segs.owner
,substr(segs.table_name,instr(segs.table_name,'.')+1) TABLE_NAME
,sum(segs.bytes) total_bytes
,sum(segs.blocks) total_blocks
,sum(case when segs.segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION','NESTED TABLE','CLUSTER') then segs.bytes end) tab_size
,sum(case when segs.segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION','CTX INDEX') then segs.bytes end) ind_size
,sum(case when segs.segment_type in ('CTX INDEX') then segs.bytes end) ctx_size
,sum(case when segs.segment_type in ('LOBSEGMENT','LOBINDEX','LOB PARTITION','LOB SUBPARTITION') then segs.bytes end) lob_size
from segs
group by owner,table_name
)
,tops as (
select
dense_rank()over (order by total_bytes desc) rnk
,so.*
from so
)
select *
from tops
where rnk<=50 -- top 50
/