
Sometimes it’s really hard even to create reproducible test case to send it to oracle support, especially in case of intermittent errors.
In such cases, I think it would be really great to have access to similar service requests or bugs of other oracle clients.
So while my poll about knowledge sharing is still active, I want to share a couple of bugs we have faced after upgrade to 12.2 (and one bug from Eric van Roon). I’m going to remove the bugs from this list when they become “public” or “fixed”.
If you want to add own findings into this list, you can add them into comments. To make this process easier, you can provide just symptomps, short description and the link to own post with details – I’ll add it just as a link.
Continue reading
Monthly Archives: November 2017
Triggers and Redo: changes on 12.2
In one of the previous posts I showed How even empty trigger increases redo generation, but running the test from that post, I have found that this behaviour a bit changed on 12.2:
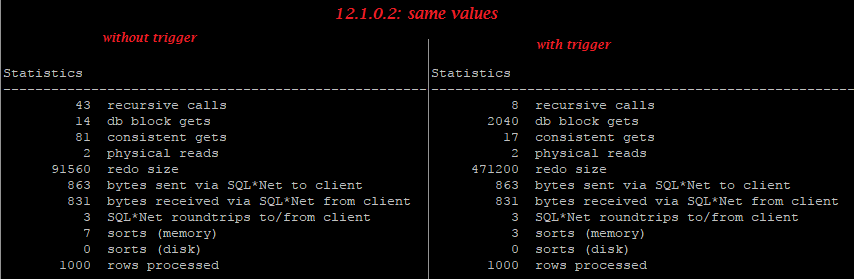
In my old test case, values of column A were equal to values of B, and on previous oracle versions including 12.1.0.2 we can see that even though “update … set B=A” doesn’t change really “B”, even empty trigger greatly increases redo generation.
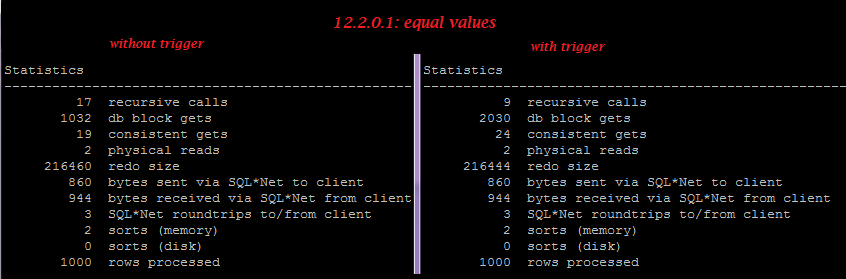
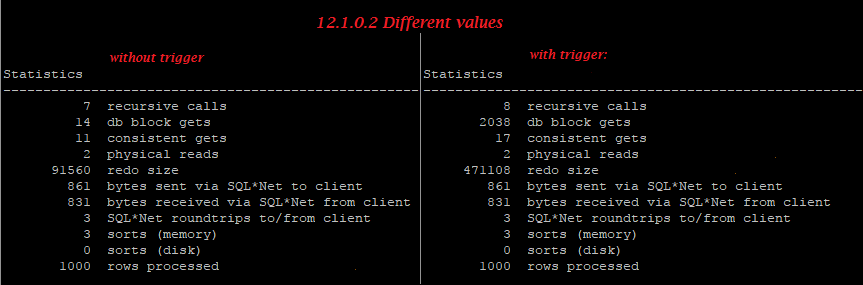
But on 12.2.0.1 in case of equal values, the trigger doesn’t increase redo, so we can see small optimization here, though in case of different values, the trigger still increases reado generation greatly.
same_dumpredo.sql
[sourcecode language=”sql”]
set feed on;
drop table xt_curr1 purge;
drop table xt_curr2 purge;
— simple table:
create table xt_curr1 as select ‘2’ a, ‘2’ b from dual connect by level<=1000;
— same table but with empty trigger:
create table xt_curr2 as select ‘2’ a, ‘2’ b from dual connect by level<=1000;
create or replace trigger tr_xt_curr2 before update on xt_curr2 for each row
begin
null;
end;
/
— objectID and SCN:
col obj1 new_val obj1;
col obj2 new_val obj2;
col scn new_val scn;
select
(select o.OBJECT_ID from user_objects o where o.object_name=’XT_CURR1′) obj1
,(select o.OBJECT_ID from user_objects o where o.object_name=’XT_CURR2′) obj2
,d.CURRENT_SCN scn
from v$database d
/
— logfile1:
alter system switch logfile;
col member new_val logfile;
SELECT member
FROM v$logfile
WHERE
is_recovery_dest_file=’NO’
and group#=(SELECT group# FROM v$log WHERE status = ‘CURRENT’)
and rownum=1;
— update1:
set autot trace stat;
update xt_curr1 set b=a;
set autot off;
commit;
— dump logfile1:
alter session set tracefile_identifier=’log1_same’;
ALTER SYSTEM DUMP LOGFILE ‘&logfile’ SCN MIN &scn OBJNO &obj1;
— logfile2:
alter system switch logfile;
col member new_val logfile;
SELECT member
FROM v$logfile
WHERE
is_recovery_dest_file=’NO’
and group#=(SELECT group# FROM v$log WHERE status = ‘CURRENT’)
and rownum=1;
— update2:
set autot trace stat;
update xt_curr2 set b=a;
set autot off;
commit;
— dump logfile2:
alter session set tracefile_identifier=’log2_same’;
ALTER SYSTEM DUMP LOGFILE ‘&logfile’ OBJNO &obj2;
alter session set tracefile_identifier=’off’;
disc;
[/sourcecode]
[collapse]
diff_dumpredo.sql
[sourcecode language=”sql”]
set feed on;
drop table xt_curr1 purge;
drop table xt_curr2 purge;
— simple table:
create table xt_curr1 as select ‘1’ a, ‘2’ b from dual connect by level<=1000;
— same table but with empty trigger:
create table xt_curr2 as select ‘1’ a, ‘2’ b from dual connect by level<=1000;
create or replace trigger tr_xt_curr2 before update on xt_curr2 for each row
begin
null;
end;
/
— objectID and SCN:
col obj1 new_val obj1;
col obj2 new_val obj2;
col scn new_val scn;
select
(select o.OBJECT_ID from user_objects o where o.object_name=’XT_CURR1′) obj1
,(select o.OBJECT_ID from user_objects o where o.object_name=’XT_CURR2′) obj2
,d.CURRENT_SCN scn
from v$database d
/
— logfile1:
alter system switch logfile;
col member new_val logfile;
SELECT member
FROM v$logfile
WHERE
is_recovery_dest_file=’NO’
and group#=(SELECT group# FROM v$log WHERE status = ‘CURRENT’)
and rownum=1;
— update1:
set autot trace stat;
update xt_curr1 set b=a;
set autot off;
commit;
— dump logfile1:
alter session set tracefile_identifier=’log1_diff’;
ALTER SYSTEM DUMP LOGFILE ‘&logfile’ SCN MIN &scn OBJNO &obj1;
— logfile2:
alter system switch logfile;
col member new_val logfile;
SELECT member
FROM v$logfile
WHERE
is_recovery_dest_file=’NO’
and group#=(SELECT group# FROM v$log WHERE status = ‘CURRENT’)
and rownum=1;
— update2:
set autot trace stat;
update xt_curr2 set b=a;
set autot off;
commit;
— dump logfile2:
alter session set tracefile_identifier=’log2_diff’;
ALTER SYSTEM DUMP LOGFILE ‘&logfile’ OBJNO &obj2;
alter session set tracefile_identifier=’off’;
disc;
[/sourcecode]
[collapse]
Equal values:
12.1.0.2:
12.2.0.1:
Different values:
12.1.0.2:
12.2.0.1:
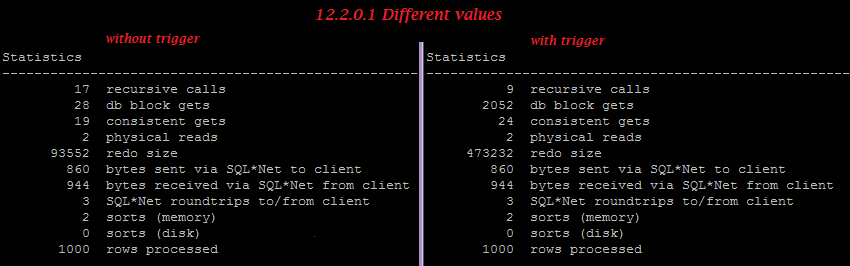
We can easily find that trigger disables batched “Array update”:

Adaptive serial direct path read decision ignores object statistics since 12.1
On versions 11.2.0.2 – 11.2.0.4 Oracle uses objects’ statistics to make direct path reads decision (of course, if “_direct_read_decision_statistics_driven” haven’t changed it to “false”), and we can force serial direct reads on statement level using sql profiles with hints INDEX_STATS/TABLES_STATS, but since at least 12.1.0.2 this decision ignores statistics.
Btw, thanks to Jure Bratina, we know now, that we need to repeat hint TABLE_STATS at least twice to make it work 🙂 And from the following test case we know that it takes parameters from second one 🙂
Compare trace files of the following test cases:
table_stats2.sql
[sourcecode language=”sql”]
drop table t1;
create table t1 as select * from dual;
—————————-
pro ######################################;
exec dbms_stats.gather_table_stats(”,’T1′);
exec dbms_stats.set_table_stats(user,’T1′,numblks => 33333333);
col value new_val oldval noprint;
select value from v$statname n, v$mystat s
where n.statistic#=s.statistic# and n.name =’physical reads direct’;
—————————-
alter session set tracefile_identifier=’table_stats2′;
–alter session set events ‘10053 trace name context forever, level 1’;
alter session set events ‘trace[nsmtio] disk highest’;
select/*+ table_stats(t1, scale, blocks=66666666 rows=2222222222)
table_stats(t1, scale, blocks=99999999 rows=4444444444)
*/
*
from t1;
select value-&oldval directreads, value from v$statname n, v$mystat s
where n.statistic#=s.statistic# and n.name =’physical reads direct’;
[/sourcecode]
[collapse]
You can see that our hint successfully changed number of blocks and forced direct path reads on 11.2.0.4:
Oracle 11.2.0.4:
[sourcecode language=”sql” highlight=”3″]
NSMTIO: qertbFetch:DirectRead:[OBJECT_SIZE>VLOT]
NSMTIO: Additional Info: VLOT=797445
Object# = 78376, Object_Size = 66666666 blocks
SqlId = 7naawntkc57yx, plan_hash_value = 3617692013, Partition# = 0
[/sourcecode]
[collapse]
But on 12.1.0.2 and 12.2.0.1 we can see 2 lines with “NSMTIO: kcbism” with the different types(2 and 3) and different number of blocks, and the direct path read decision was based on second one – from segment header:
Oracle 12.1.0.2:
[sourcecode language=”sql” highlight=”1,2″]
NSMTIO: kcbism: islarge 1 next 0 nblks 66666666 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 4096 kcbstt 983 keep_nb 0 kcbnbh 59010 kcbnwp 1
NSMTIO: kcbism: islarge 0 next 0 nblks 4 type 2, bpid 3, kcbisdbfc 0 kcbnhl 4096 kcbstt 983 keep_nb 0 kcbnbh 59010 kcbnwp 1
NSMTIO: qertbFetch:NoDirectRead:[- STT < OBJECT_SIZE < MTT]:Obect’s size: 4 (blocks), Threshold: MTT(4917 blocks),
_object_statistics: enabled, Sage: enabled,
Direct Read for serial qry: enabled(::::::), Ascending SCN table scan: FALSE
flashback_table_scan: FALSE, Row Versions Query: FALSE
SqlId: 7naawntkc57yx, plan_hash_value: 3617692013, Object#: 302342, Parition#: 0 DW_scan: disabled
[/sourcecode]
[collapse]
Oracle 12.2.0.1:
[sourcecode language=”sql” highlight=”1,2″]
NSMTIO: kcbism: islarge 1 next 0 nblks 66666666 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 4096 kcbstt 1214 keep_nb 0 kcbnbh 45026 kcbnwp 1
NSMTIO: kcbism: islarge 0 next 0 nblks 4 type 2, bpid 3, kcbisdbfc 0 kcbnhl 4096 kcbstt 1214 keep_nb 0 kcbnbh 45026 kcbnwp 1
NSMTIO: qertbFetch:NoDirectRead:[- STT < OBJECT_SIZE < MTT]:Obect’s size: 4 (blocks), Threshold: MTT(6072 blocks),
_object_statistics: enabled, Sage: enabled,
Direct Read for serial qry: enabled(:::::::), Ascending SCN table scan: FALSE
flashback_table_scan: FALSE, Row Versions Query: FALSE
SqlId: 7naawntkc57yx, plan_hash_value: 3617692013, Object#: 174411, Parition#: 0 DW_scan: disabled
[/sourcecode]
[collapse]
And similar example, but for IFFS(index fast full scan):
nb: I set the number of index blocks using dbms_stats to 33333000 and hinted the query with 77777700
index_stats2.sql
[sourcecode language=”sql”]
drop table t2 purge;
ALTER SESSION SET optimizer_dynamic_sampling = 0;
ALTER SESSION SET "_optimizer_use_feedback" = FALSE;
ALTER SESSION SET optimizer_adaptive_features = FALSE;
ALTER SESSION SET optimizer_adaptive_plans=FALSE;
create table t2(x) as select level from dual connect by level<=1000;
create index t2_ix on t2(1,x,rpad(x,100));
begin
dbms_stats.gather_table_stats(”,’T2′,cascade => true);
dbms_stats.set_table_stats(user,’T2′ ,numblks => 33333333);
dbms_stats.set_index_stats(user,’T2_IX’,numlblks => 33333000);
end;
/
col value new_val oldval noprint;
select value from v$statname n, v$mystat s
where n.statistic#=s.statistic# and n.name =’physical reads direct’;
alter session set tracefile_identifier=’index_stats2′;
alter session set events ‘trace[nsmtio] disk highest’;
select/*+ index_stats(t2, t2_ix, scale, blocks=7777700)
index_ffs(t2 t2_ix)
dynamic_sampling(0)
*/
count(*) cnt2
from t2;
select value-&oldval directreads, value from v$statname n, v$mystat s
where n.statistic#=s.statistic# and n.name =’physical reads direct’;
disc;
[/sourcecode]
[collapse]
You can see that on 11.2.0.4 oracle gets number of blocks from the hint (7777700)
Oracle 11.2.0.4 - index_stats:
[sourcecode language=”sql” highlight=”2″]
NSMTIO: qerixFetchFastFullScan:DirectRead[OBJECT_SIZE > VLOT]:
NSMTIO: AdditionalInfo: Object_size: 7777700 (blocks), vlot=797445
SqlId=by2zv0k566hj5, plan_hash_value=3419274230,Object#=78375
[/sourcecode]
[collapse]
From the first line we can see that kcbism takes the hinted number of blocks, but later kcbivlo rewrites it with the number from segment header:
Oracle 12.1.0.2 - index_stats:
[sourcecode language=”sql” highlight=”2″]
NSMTIO: kcbism: islarge 1 next 0 nblks 7777700 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 4096 kcbstt 983 keep_nb 0 kcbnbh 59010 kcbnwp 1
NSMTIO: kcbivlo: nblks 22 vlot 500 pnb 49175 kcbisdbfc 0 is_large 0
NSMTIO: qerixFetchFastFullScan:[MTT < OBJECT_SIZE < VLOT]:NSMTIO: AdditionalInfo: Object_size: 22 (blocks), vlot=245875
SqlId=by2zv0k566hj5, plan_hash_value=3419274230,Object#=302347
[/sourcecode]
[collapse]
Oracle 12.2.0.1 - index_stats:
[sourcecode language=”sql” highlight=”2″]
NSMTIO: kcbism: islarge 1 next 0 nblks 7777700 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 4096 kcbstt 1214 keep_nb 0 kcbnbh 45026 kcbnwp 1
NSMTIO: kcbivlo: nblks 22 vlot 500 pnb 60729 kcbisdbfc 0 is_large 0
NSMTIO: qerixFetchFastFullScan:[MTT < OBJECT_SIZE < VLOT]:NSMTIO: AdditionalInfo: Object_size: 22 (blocks), vlot=303645
SqlId=by2zv0k566hj5, plan_hash_value=3419274230,Object#=174409
[/sourcecode]
[collapse]
So we have 2 options to force direct reads:
1. to execute alter session set “_serial_direct_read”=’ALWAYS’;
2. or to force parallel plan to get parallel direct path reads (we can do it with even with dop=1)
Easy(lazy) way to check which programs have properly configured FetchSize
select
s.module
,ceil(max(s.rows_processed/s.fetches)) rows_per_fetch
from v$sql s
where
s.rows_processed>100
and s.executions >1
and s.fetches >1
and s.module is not null
and s.command_type = 3 -- SELECTs only
and s.program_id = 0 -- do not account recursive queries from stored procs
and s.parsing_schema_id!=0 -- <> SYS
group by s.module
order by rows_per_fetch desc nulls last
/
Revisiting buffer cache Very Large Object Threshold
If you turn on NSMTIO tracing you will see references to VLOT:
qertbFetch:[MTT < OBJECT_SIZE < VLOT]: Checking cost to read from caches (local/remote) and checking storage reduction factors (OLTP/EHCC Comp)
I had said you could ignore VLOT and Frits Hoogland pointed out that tracing showed it had some impact, so let me clarify:
VLOT is the absolute upper bound that cached reads can even be considered.
This defaults to 500% of the number of buffers in the cache i.e.
_very_large_object_threshold = 500
While this number is not used in any calculations, it is used in two places as a cutoff to consider those calculations
1) Can we consider using Automatic Big Table Caching (a.k.a. DWSCAN) for this object?
2) Should we do a cost analysis for Buffer Cache scan vs Direct Read scan on tables larger than the MTT?
The logic for tables above the calculated medium table threshold (MTT) and that are NOT part of searched DMLs and are NOT on Exadata with statistics based storage reduction factor enabled (_statistics_based_srf_enabled) is:
- If _serial_direct_read == ALWAYS, use Direct Read
- If _serial_direct_read == NEVER, use Buffer Cache
- If _serial_direct_read == AUTO and #blocks in table < VLOT, use cost model
- Else use Direct Read “qertbFetch:DirectRead:[OBJECT_SIZE>VLOT]”
In practice 5X buffer cache is so large the cost based decision will come to the same conclusion anyway – the default VLOT simply saves time spent doing the analysis.
For example, I got a quick count of the number of blocks in non-partitioned TPC_H Scale 1 lineitem
select segment_name,sum(blocks),sum(bytes) from user_extents where segment_name='LINEITEM'
and created my buffer cache to be exactly the same size. With this setup, setting _very_large_object_threshold=100 bypassed the cost model and went straight to DR scan, while setting it to 200 forced the use of the cost model.
The moral of this is that the default value of VLOT rarely changes the decisions made unless you reduce VLOT to a much smaller multiplier of the cache size and can start to see it cause a few more of your larger buffer cache scans move to direct read when they are no longer eligible for cost analysis. If you wish to stop some of the largest buffer cache scans from happening you would need to set _very_large_object_threshold less than 200.
Random thoughts on block sizes
I heard “Oracle only tests on 8k and doesn’t really test 16k”
I heard someone assert that one reason you should only use 8k block sizes is that, and I quote, “Oracle only tests on 8k and doesn’t really test 16k”. I tried googling that rumour and tracked it back to AskTom. Also as disks and memory get bigger and CPUs get faster it is natural to ask if 8k is now “too small”.
So here are my thoughts:
1. A quick scan of the data layer regression tests showed a very large number running on 16k blocks
2. Oracle typically runs it DW stress tests on 16k blocks
So, clearly, the assertion is untrue but I did spot some areas where 32k testing could be improved. I also added a note to AskTom clarifying testing on 16k.
Does this mean I should look at using 16k blocks for me DW
Whoa, not so fast. Just because table scans typically run slightly faster on 16k blocks and compression algorithms typically get slightly better compression on 16k blocks does not mean your application will see improvements
1. Multiple block sizes mean added work for the DBA
2. Databases do a lot more than just scan tables – e.g. row based writes and reads could perform worse
3. Most apps have low hanging fruit that will give you far better ROI on your time than worrying about block sizes (if you don’t believe me, attend one of Jonathan Lewis’s excellent index talks).
Most applications run fine on 8k because it is a good trade off between different access paths and, in general, 8k is still the right choice for most applications.
What about ‘N’ row pieces
In general Oracle’s block layout tries to ensure row pieces are split on column boundaries but in the case of very wide columns we will split in the middle of a column if too much space would be wasted by aligning with column boundaries. When a column is split in the middle it creates what is known as an ‘N’ row piece.
Rows are split by default at 255 column boundaries assuming the row piece fits in the block If you have a table with very wide rows or some very wide inline columns, smaller block sizes will result both in rows being split more often and in columns being split in the middle. At a minimum the number of block gets to retrieve a single row will likely increase. This is one case to consider where a 16k block size may be worth investigating.
The curious case of 70X compression
We had case of a customer legitimately point out that ZLIB would give much better than 70X compression on his very repetitive data but COMPRESS FOR QUERY HIGH was stuck at 70X. And, as it turns out, this is a factor of block size.
Hybrid Columnar Compression (HCC) takes up to 8 MB of raw data and compresses it down to one CU (Compression Unit) subject to row limits depending on compression type. For example COMPRESS FOR ARCHIVE LOW (which is also ZLIB) is limited to 8,000 rows in a CU. But there is another limit which you may deduce from block dumps which is that HCC will only allow one head piece row per block because HCC rowids are the RDBA of the head piece plus the row offset into the CU. So if you have incredibly compressible data where 8,000 rows compress down to less 16k moving to a larger block size can be bad news because you will end up with wasted space at the end of each block.
Summary
There are typically better things to spend time on than worrying about block size but if you wish to run your DW on 16k blocks they are thoroughly tested just like 8k blocks are.