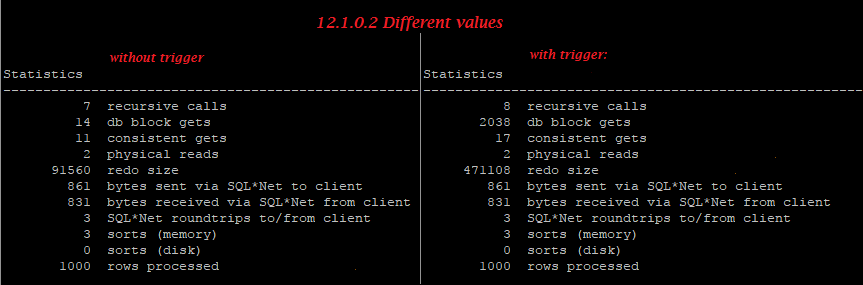
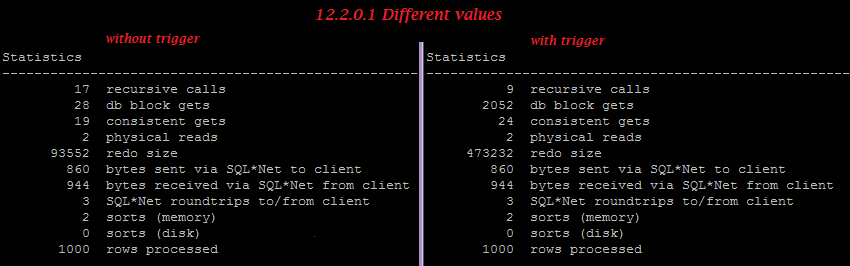
Recently I had to install the patch for fixing cross-platform PDB transport bug onto the docker images with Oracle, so these are easy way how to do it:
1. create directory “patches” and create “install_patches.sh”:
#!/bin/bash
unzip -u ./*.zip
CURDIR=`pwd`
for D in *; do
if [ -d "${D}" ]; then
echo =================================================
echo " *** Processing patch # ${D}... " # your processing here
cd "${D}"
opatch apply -silent
fi
cd $CURDIR
done
2. add the following commands into the dockerfile:
USER root
# Copy DB install file
COPY --chown=oracle:dba patches $INSTALL_DIR/patches
# Install DB software binaries
USER oracle
RUN chmod ug+x $INSTALL_DIR/patches/*.sh && \
sync && \
cd $INSTALL_DIR/patches && \
./install_patches.sh
3. put downloaded patches into the “patches” directory and build image.
For example, dockerfile for 18.3:
FROM oracle/database:18.3.0-ee
MAINTAINER Sayan Malakshinov <sayan@orasql.org>
USER root
# Copy patches:
COPY --chown=oracle:dba patches $INSTALL_DIR/patches
# Install patches:
USER oracle
RUN chmod ug+x $INSTALL_DIR/patches/*.sh && \
sync && \
cd $INSTALL_DIR/patches && \
./install_patches.sh
ps. I’ve also create the request for that in the official Docker github: https://github.com/oracle/docker-images/issues/1070