One of the easiest ways is to use diagnostic events:
alter session set events 'sql_trace {callstack: fname xctend} errorstack(1)';
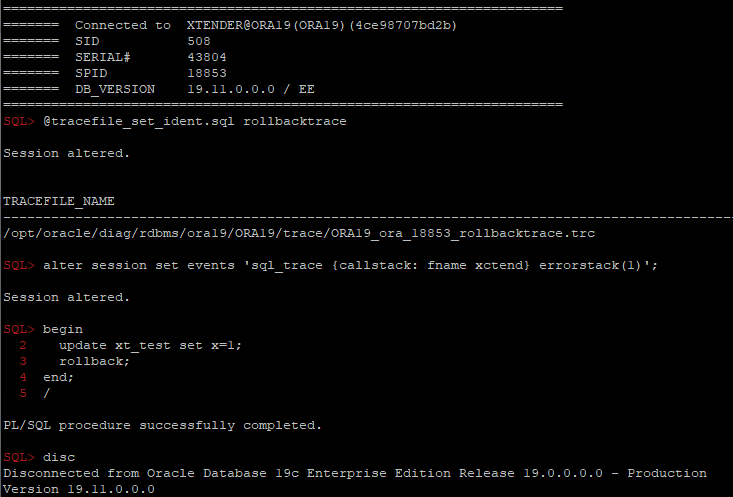
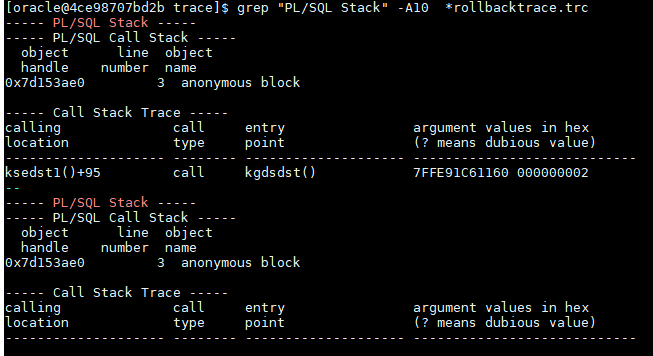

One of the easiest ways is to use diagnostic events:
alter session set events 'sql_trace {callstack: fname xctend} errorstack(1)';
I know 2 “special” exceptions that can’t be processed in exception handler:
Tanel Poder described the first one (ORA-01013) in details here: https://tanelpoder.com/2010/02/17/how-to-cancel-a-query-running-in-another-session/ where Tanel shows that this error is based on SIGURG signal (kill -URG):
-- 1013 will not be caught:
declare
e exception;
pragma exception_init(e,-1013);
begin
raise e;
exception when others then dbms_output.put_line('caught');
end;
/
declare
*
ERROR at line 1:
ORA-01013: user requested cancel of current operation
ORA-06512: at line 5
Got an interesting question today in RuOUG:
Some very simple PL/SQL procedures usually are completed within ~50ms, but sometimes sporadically longer than a second. For example, the easiest one from these procedures:
create or replace PROCEDURE XXXX (
P_ORG_NUM IN number,
p_result OUT varchar2,
p_seq OUT number
) AS
BEGIN
p_seq := P_ORG_NUM; p_result:='';
END;
sql_trace shows that it was executed for 1.001sec and all the time was “ON CPU”:
Continue readingObviously we can format/beautify SQL or PL/SQL code using external tools, but sometimes it would be more convenient to format it directly in database, for example if we want to see few different sql_text’s from v$sqlarea. And thanks to Oracle SqlCL and Oracle SQL Developer, we can easily use oracle.dbtools.app.Format function from their Java library dbtools-common.jar, so if you use SqlCL or SQL Developer, you can use the same formatting options.
You may have already installed SQLDeveloper or SqlCL on your database server, just check $ORACLE_HOME/sqldeveloper or $ORACLE_HOME/sqcl directories. If – not, you need to download appropriate SqlCL version that matches your java version in Oracle. For 12.2 – 19.8 you can download latest SqlCL 20.3. In fact we need just dbtools-common.jar from lib directory. I put it into $ORACLE_HOME/sqlcl/lib directory on the server and load it using loadjava:
Continue readingYou may know that whenever you call PL/SQL functions from within SQL query, each query in the function is consistent to the SCN of its start and not to the SCN of parent query.
Simple example:
create table test as
select level a, level b from dual connect by level<=10;
create or replace function f1(a int) return int as
res int;
begin
select b into res
from test t
where t.a=f1.a;
dbms_lock.sleep(1);
return res;
end;
/
As you can see we created a simple PL/SQL function that returns the result of the query select b from test where a=:input_var
But lets check what does it return if another session changes data in the table:
-- session 2:
begin
for i in 1..30 loop
update test set b=b+1;
commit;
dbms_lock.sleep(1);
end loop;
end;
/
-- session 1:
SQL> select t.*, f1(a) func from test t;
A B FUNC
---------- ---------- ----------
1 1 1
2 2 3
3 3 5
4 4 7
5 5 9
6 6 11
7 7 13
8 8 15
9 9 17
10 10 19
10 rows selected.
As you can see we got inconsistent results in the column FUNC, but we can easily fix it using OPERATORs:
CREATE OPERATOR f1_op
BINDING (INT)
RETURN INT
USING F1;
Lets revert changes back and check our query with new operator now:
--session 1:
SQL> update test set b=a;
10 rows updated.
SQL> commit;
Commit complete.
-- session 2:
begin
for i in 1..30 loop
update test set b=b+1;
commit;
dbms_lock.sleep(1);
end loop;
end;
/
-- session 1:
SQL> select t.*, f1(a) func, f1_op(a) op from test t;
A B FUNC OP
---------- ---------- ---------- ----------
1 2 2 2
2 3 5 3
3 4 8 4
4 5 11 5
5 6 14 6
6 7 17 7
7 8 20 8
8 9 23 9
9 10 26 10
10 11 29 11
10 rows selected.
As you can see, all values in the column OP are equal to the values of B, while, in turn, function F1 returns inconsistent values.
Alex R recently discovered interesting thing: in SQL pipelined functions work much faster than simple non-pipelined table functions, so if you already have simple non-pipelined table function and want to get its results in sql (select * from table(fff)), it’s much better to create another pipelined function which will get and return its results through PIPE ROW().
A bit more details:
Assume we need to return collection “RESULT” from PL/SQL function into SQL query “select * from table(function_F(…))”.
If we create 2 similar functions: pipelined f_pipe and simple non-pipelined f_non_pipe,
create or replace function f_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
begin
...
for i in 1..n loop
pipe row (result(i));
end loop;
end f_pipe;
/
create or replace function f_non_pipe(n int) return tt_id_value
as
result tt_id_value;
begin
...
return result;
end f_non_pipe;
/
[sourcecode language=”sql”]
create or replace type to_id_value as object (id int, value int)
/
create or replace type tt_id_value as table of to_id_value
/
create or replace function f_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
for i in 1..n loop
pipe row (result(i));
end loop;
end f_pipe;
/
create or replace function f_non_pipe(n int) return tt_id_value
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
return result;
end f_non_pipe;
/
create or replace function f_pipe_for_nonpipe(n int) return tt_id_value pipelined
as
result tt_id_value;
begin
result:=f_non_pipe(n);
for i in 1..result.count loop
pipe row (result(i));
end loop;
end;
/
create or replace function f_udf_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
for i in 1..n loop
pipe row (result(i));
end loop;
end;
/
create or replace function f_udf_non_pipe(n int) return tt_id_value
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
return result;
end;
/
[/sourcecode]
[sourcecode language=”sql”]
set echo on feed only timing on;
–alter session set optimizer_adaptive_plans=false;
–alter session set "_optimizer_use_feedback"=false;
select sum(id * value) s from table(f_pipe(&1));
select sum(id * value) s from table(f_non_pipe(&1));
select sum(id * value) s from table(f_pipe_for_nonpipe(&1));
select sum(id * value) s from table(f_udf_pipe(&1));
select sum(id * value) s from table(f_udf_non_pipe(&1));
with function f_inline_non_pipe(n int) return tt_id_value
as
result tt_id_value;
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
return result;
end;
select sum(id * value) s from table(f_inline_non_pipe(&1));
/
set timing off echo off feed on;
[/sourcecode]
| Function | 1 000 000 elements | 100 000 elements |
|---|---|---|
| F_PIPE | 2.46 | 0.20 |
| F_NON_PIPE | 4.39 | 0.44 |
| F_PIPE_FOR_NONPIPE | 2.61 | 0.26 |
| F_UDF_PIPE | 2.06 | 0.20 |
| F_UDF_NON_PIPE | 4.46 | 0.44 |
I was really surprised that even “COLLECTION ITERATOR PICKLER FETCH” with F_PIPE_FOR_NONPIPE that gets result of F_NON_PIPE and returns it through PIPE ROW() works almost twice faster than F_NON_PIPE, so I decided to analyze it using stapflame by Frits Hoogland.
I added “dbms_lock.sleep(1)” into both of these function after collection generation, to compare the difference only between “pipe row” in loop and “return result”:
[sourcecode language=”sql”]
create or replace function f_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
dbms_lock.sleep(1);
for i in 1..n loop
pipe row (result(i));
end loop;
end f_pipe;
/
create or replace function f_non_pipe(n int) return tt_id_value
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
dbms_lock.sleep(1);
return result;
end f_non_pipe;
/
[/sourcecode]
And stapflame showed that almost all overhead was consumed by the function “kgmpoa_Assign_Out_Arguments”:
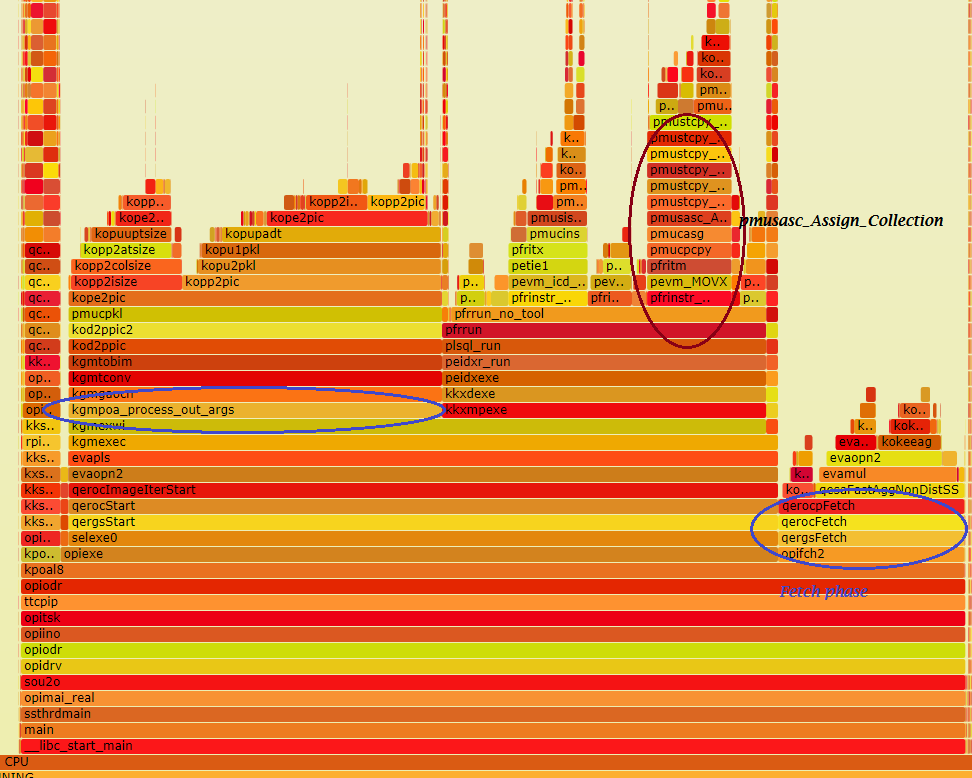
I don’t know what this function is doing exactly, but we can see that oracle assign collection a bit later.
From other functions in this stack(pmucpkl, kopp2isize, kopp2colsize, kopp2atsize(attribute?), kopuadt) I suspect that is some type of preprocessiong of return arguments.
What do you think about it?
Full stapflame output:
stapflame_nonpipe
stapflame_pipe
This interesting question was posted on our russian forum yesterday:
We have a huge PL/SQL package and this simple function returns wrong result when it’s located at the end of package body:
create or replace package body PKGXXX as ... function ffff return number is nRes number; begin nRes := 268435456; return nRes; end; end; /But it works fine in any of the following cases:
* replace 268435456 with power(2, 28), or
* replace 268435456 with small literal like 268, or
* move this function to the beginning of package body
The one of the interesting findings was that the returned value is equal to the one of literals in another function.
We can reproduce this bug even with an anonymous pl/sql block. The following test case uses 32768 integer literals from 1000001 to 1032768 and prints 5 other integers:
declare n number;
begin
n:=1000001; -- this part
n:=1000002; -- creates
n:=1000003; -- 32768
... -- integer
n:=1032768; -- literals
dbms_output.put_line('100000='||100000); -- it should print: 100000=100000
dbms_output.put_line('32766 ='||32766);
dbms_output.put_line('32767 ='||32767);
dbms_output.put_line('32768 ='||32768);
dbms_output.put_line('32769 ='||32769);
end;
[sourcecode language=”sql”]
declare
c clob:=’declare n number;begin’||chr(10);
f varchar2(100):=’n:=%s;’||chr(10);
v varchar2(32767);
n number:=32768;
begin
for i in 1..n loop
v:=v||utl_lms.format_message(f,to_char(1e7+i));
if length(v)>30000 then
c:=c||v;
v:=”;
end if;
end loop;
v:=v||q'[
dbms_output.put_line(‘100000=’||100000);
dbms_output.put_line(‘32766 =’||32766);
dbms_output.put_line(‘32767 =’||32767);
dbms_output.put_line(‘32768 =’||32768);
dbms_output.put_line(‘32769 =’||32769);
end;
]’;
c:=c||v;
execute immediate c;
end;
/
[/sourcecode]
100000=10000001 32766 =32766 32767 =32767 32768 =10000002 32769 =10000003
This test case well demonstrates wrong results:
* instead of 100000 we get 10000001, which is the value from first line after “begin”, ie 1st integer literal in the code,
* for 32766 and 32767 oracle returns right values
* instead of 32768 (==32767+1) it returns 10000002, which is the integer from 2nd line, ie 2nd integer literal in the code,
* instead of 32769 (==32767+2) it returns 10000003, which is the integer from 3rd line, ie 3rd integer literal in the code
After several tests I can make a conclusion:
So we can describe this behaviour using first test case:
declare n number;
begin
n:=1000001; -- this part
n:=1000002; -- creates
n:=1000003; -- 32768
... -- integer
n:=1032768; -- literals
dbms_output.put_line('100000='||100000); -- it should print 100000, ie 32768th element of array, but prints 10000001
-- where 10000001 is the 1st element of array (1==mod(32768,32767))
dbms_output.put_line('32766 ='||32766); -- these 2 lines print right values,
dbms_output.put_line('32767 ='||32767); -- because their values are in the range of -32768..32767
dbms_output.put_line('32768 ='||32768); -- this line contains 32769th element and prints 2nd element of array (2==mod(32769,32767))
dbms_output.put_line('32769 ='||32769); -- this line contains 32770th element and prints 3nd element of array (3==mod(32770,32767))
end;
The following query can help you to find objects which can potentially have this problem:
select
s.owner,s.name,s.type
,sum(regexp_count(text,'(\W|^)3\d{4,}([^.0-9]|$)')) nums_count -- this regexp counts integer literals >= 30000
from dba_source s
where
owner='&owner'
and type in ('FUNCTION','PROCEDURE','PACKAGE','PACKAGE BODY')
group by s.owner,s.name,s.type
having sum(regexp_count(text,'(\W|^)3\d{4,}([^.0-9]|$)'))>32767 -- filter only objects which have >=32767 integer literal
Workaround:
You may noticed that I wrote about INTEGER literals only, so the easiest workaround is to make them FLOAT – just add “.” to the end of each literal:
declare n number;
begin
n:=1000001.;
n:=1000002.;
n:=1000003.;
...
n:=1032768.;
dbms_output.put_line('100000='||100000.);
dbms_output.put_line('32766 ='||32766.);
dbms_output.put_line('32767 ='||32767.);
dbms_output.put_line('32768 ='||32768.);
dbms_output.put_line('32769 ='||32769.);
end;
[sourcecode language=”sql”]
declare
c clob:=’declare n number;begin’||chr(10);
f varchar2(100):=’n:=%s.;’||chr(10); — I’ve added here "."
v varchar2(32767);
n number:=32768;
begin
for i in 1..n loop
v:=v||utl_lms.format_message(f,to_char(1e7+i));
if length(v)>30000 then
c:=c||v;
v:=”;
end if;
end loop;
v:=v||q'[
dbms_output.put_line(‘100000=’||100000.); — .
dbms_output.put_line(‘32766 =’||32766.);
dbms_output.put_line(‘32767 =’||32767.);
dbms_output.put_line(‘32768 =’||32768.);
dbms_output.put_line(‘32769 =’||32769.);
end;
]’;
c:=c||v;
execute immediate c;
end;
/
[/sourcecode]
Unfortunately associative arrays still require more “coding”:
we still can’t use “indices of” or “values of” in simple FOR(though they are available for FORALL for a long time), don’t have convinient iterators and even function to get all keys…
That’s why I want to show my templates for such things like iterator and keys function. You can adopt these functions and create them on schema level.
declare
type numbers is table of number;
type anumbers is table of number index by pls_integer;
a anumbers;
i pls_integer;
function iterate( idx in out nocopy pls_integer, arr in out nocopy anumbers)
return boolean
as pragma inline;
begin
if idx is null
then idx:=arr.first;
else idx:=arr.next(idx);
end if;
return idx is not null;
end;
function keys(a in out nocopy anumbers) return numbers as
res numbers:=numbers();
idx number;
pragma inline;
begin
while iterate(idx,a) loop
res.extend;
res(res.count):=idx;
end loop;
return res;
end;
begin
a(1):=10;
a(3):=30;
a(5):=50;
a(8):=80;
-- iterate:
while iterate(i,a) loop
dbms_output.put_line(a(i));
end loop;
-- keys:
for i in 1..keys(a).count loop
dbms_output.put_line(a(keys(a)(i)));
end loop;
end;
I see quite often when developers ask questions about connected components:
| Table “MESSAGES” contains fields “SENDER” and “RECIPIENT”, which store clients id. How to quickly get all groups of clients who are connected even through other clients if the table has X million rows? So for this table, there should be 4 groups:
|
|
Of course, we can solve this problem using SQL only (model, recursive subquery factoring or connect by with nocycle), but such solutions will be too slow for huge tables.
[sourcecode language=”sql”]
with
t(sender,recipient) as (select level,level*2 from dual connect by level<=10)
, v1 as (select rownum id,t.* from t)
, v2 as (select id, account
from v1
unpivot (
account for x in (sender,recipient)
))
, v3 as (
select
id
,account
,dense_rank()over(order by account) account_n
,count(*)over() cnt
from v2)
, v4 as (
select distinct grp,account
from v3
model
dimension by (id,account_n)
measures(id grp,account,cnt)
rules
iterate(1e6)until(iteration_number>cnt[1,1])(
grp[any,any] = min(grp)[any,cv()]
,grp[any,any] = min(grp)[cv(),any]
)
)
select
listagg(account,’,’)within group(order by account) s
from v4
group by grp
[/sourcecode]
It contains 2 functions based on Weighted quick-find quick-union algorithm:
select * from table(xt_connected_components.get_strings( cursor(select ELEM1||','||ELEM2 from TEST));
select *
from
table(
xt_connected_components.get_strings(
cursor(select 'a,b,c' from dual union all
select 'd,e,f' from dual union all
select 'e,c' from dual union all
select 'z' from dual union all
select 'X,Y' from dual union all
select 'Y,Z' from dual)));
COLUMN_VALUE
-----------------------------------------
STRINGS('X', 'Y', 'Z')
STRINGS('a', 'b', 'c', 'd', 'e', 'f')
STRINGS('z')
select *
from table(
xt_connected_components.get_numbers(
cursor(
select sender_id, recipient_id from messages
)));
select *
from
table(
xt_connected_components.get_numbers(
cursor(
select level account1
, level*2 account2
from dual
connect by level<=10
)));
SQL> select *
2 from
3 table(
4 xt_connected_components.get_numbers(
5 cursor(
6 select level account1
7 , level*2 account2
8 from dual
9 connect by level<=10
10* )))
SQL> /
COLUMN_VALUE
------------------------
NUMBERS(1, 2, 4, 8, 16)
NUMBERS(3, 6, 12)
NUMBERS(5, 10, 20)
NUMBERS(7, 14)
NUMBERS(9, 18)
How to install:
Download all files from Github and execute “@install” in SQL*Plus or execute them in another tool in the following order:
xt_connected_components_types.sql
xt_connected_components_pkg.sql
xt_connected_components_bdy.sql
Download URL: https://github.com/xtender/xt_scripts/tree/master/extra/xt_connected_components
A recent posting on SQL.RU asked why Oracle doesn’t raise such errors like “ORA-00979 not a group by expression” during PL/SQL compilation. Since I couldn’t find a link to the answer (though I read about it many years ago, but I don’t remember where…), I’ve decided to post short answer:
During PL/SQL compilation Oracle checks static SQL using only:
And since Oracle doesn’t validate all other types of errors during Syntactic and Semantic analysis, we can detect them only during optimization* or execution*.
For example, Oracle detects “ORA-00979 not a group by expression” during optimization phase.
NB. It doesn’t not apply to CREATE or ALTER VIEW, because Oracle executes optimization step for them. You can check it using trace 10053.
Simple example:
-- fORm instead of "from" - syntactic validation fails:
SQL> create table t(a int, b int, c int);
SQL> create or replace procedure p_syntactic is
2 cursor c is select a,b,sum(c) sum_c fORm t group by a;
3 begin
4 null;
5 end;
6 /
Warning: Procedure created with compilation errors.
SQL> sho error;
Errors for PROCEDURE P_SYNTACTIC:
LINE/COL ERROR
-------- -----------------------------------------------------------------
2/16 PL/SQL: SQL Statement ignored
2/40 PL/SQL: ORA-00923: FROM keyword not found where expected
-- semantic validation fails:
SQL> create or replace procedure p_semantic is
2 cursor c is select a,b,sum(blabla) sum_c from t group by a;
3 begin
4 null;
5 end;
6 /
Warning: Procedure created with compilation errors.
SQL> sho error;
Errors for PROCEDURE P_SEMANTIC:
LINE/COL ERROR
-------- -----------------------------------------------------------------
2/16 PL/SQL: SQL Statement ignored
2/31 PL/SQL: ORA-00904: "BLABLA": invalid identifier
-- As you can see this procedure passes successfully both syntactic and semantic analysis,
-- though query is not valid: it should raise "ORA-00979: not a GROUP BY expression"
SQL> create or replace procedure p_valid is
2 cursor c is select a,b,sum(c) sum_c from t group by a;
3 begin
4 null;
5 end;
6 /
SQL> sho error;
No errors.
-- Oracle checks such errors for "CREATE VIEW", because it runs optimization for the query text:
SQL> create view v_cursor as select a,b,sum(c) sum_c from t group by a order by a;
create view v_cursor as select a,b,sum(c) sum_c from t group by a order by a
*
ERROR at line 1:
ORA-00979: not a GROUP BY expression