
I think you know the famous print_table procedure by Tom Kyte. It is really great, but a little hard(it requires create procedure or place it in anonymous block) and in last oracle versions we can do same with one simple query with xmltable/xmlsequence:
SQL> select * 2 from 3 xmltable( '/ROWSET/ROW/*' 4 passing xmltype(cursor(select * from hr.employees where rownum<3)) 5 columns 6 col varchar2(100) path 'name()' 7 ,val varchar2(100) path '.' 8 ); COL VAL ------------------------------ ------------------------------------------------------ EMPLOYEE_ID 198 FIRST_NAME Donald LAST_NAME OConnell EMAIL DOCONNEL PHONE_NUMBER 650.507.9833 HIRE_DATE 21-JUN-07 JOB_ID SH_CLERK SALARY 2600 MANAGER_ID 124 DEPARTMENT_ID 50 EMPLOYEE_ID 199 FIRST_NAME Douglas LAST_NAME Grant EMAIL DGRANT PHONE_NUMBER 650.507.9844 HIRE_DATE 13-JAN-08 JOB_ID SH_CLERK SALARY 2600 MANAGER_ID 124 DEPARTMENT_ID 50 20 rows selected.
It is very easy, but for conveniency we need to add “rownum”:
SQL> select *
2 from
3 xmltable( 'for $a at $i in /ROWSET/ROW
4 ,$r in $a/*
5 return element ROW{
6 element ROW_NUM{$i}
7 ,element COL_NAME{$r/name()}
8 ,element COL_VALUE{$r/text()}
9 }'
10 passing xmltype(cursor(select * from hr.employees where rownum<3))
11 columns
12 row_num int
13 ,col_name varchar2(30)
14 ,col_value varchar2(100)
15 );
ROW_NUM COL_NAME COL_VALUE
---------- ------------------------------ ------------------------------------------
1 EMPLOYEE_ID 198
1 FIRST_NAME Donald
1 LAST_NAME OConnell
1 EMAIL DOCONNEL
1 PHONE_NUMBER 650.507.9833
1 HIRE_DATE 21-JUN-07
1 JOB_ID SH_CLERK
1 SALARY 2600
1 MANAGER_ID 124
1 DEPARTMENT_ID 50
2 EMPLOYEE_ID 199
2 FIRST_NAME Douglas
2 LAST_NAME Grant
2 EMAIL DGRANT
2 PHONE_NUMBER 650.507.9844
2 HIRE_DATE 13-JAN-08
2 JOB_ID SH_CLERK
2 SALARY 2600
2 MANAGER_ID 124
2 DEPARTMENT_ID 50
20 rows selected.
Now we can create simple script for it with formatting:
[sourcecode language=”sql”]
— show output
set termout on
— but without echo
set echo off
— without newpage on start:
set embedded on
— scrolling control
set pause on
— two lines between rows:
set newpage 2
— text for prompt after each page:
set pause "Press Enter to view next row…"
— new page on new "row_num"
break on row_num skip page
— main query:
select *
from
xmltable( ‘for $a at $i in /ROWSET/ROW
,$r in $a/*
return element ROW{
element ROW_NUM{$i}
,element COL_NAME{$r/name()}
,element COL_VALUE{$r/text()}
}’
passing xmltype(cursor( &1 ))
columns
row_num int
,col_name varchar2(30)
,col_value varchar2(100)
);
— disabling pause and breaks:
set pause off
clear breaks
[/sourcecode]
Usage example:
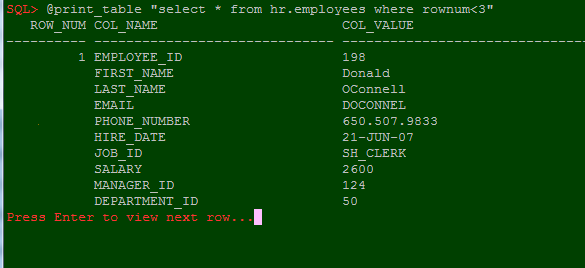
As you see script works fine, but it is require to pass query as parameter, though sometimes it is not so convenient. For example if we want started query and later decided to show it with print_table. In that case we can create scripts with tricks from previous part:
[sourcecode language=”sql”]
store set settings.sql replace
— saving previous query:
save tmp.sql replace
— OS-dependent removing trailing slash from file, choose one:
— 1. for *nix through head:
!head -1 tmp.sql >tmp2.sql
— 2. for for *nix through grep:
–!grep -v tmp.sql >tmp2.sql
— 3. for windows without grep and head:
— $cmd /C findstr /v /C:"/" tmp.sql > tmp2.sql
— 4. for windows with "head"(eg from cygwin)
–$cmd /C head -1 tmp.sql > tmp2.sql
— 5. for windows with "grep":
–$cmd /C grep -v "/" tmp.sql > tmp2.sql
— same setting as in print_table:
set termout on echo off embedded on pause on newpage 2
set pause "Press Enter to view next row…"
break on row_num skip page
— main query:
select *
from
xmltable( ‘for $a at $i in /ROWSET/ROW
,$r in $a/*
return element ROW{
element ROW_NUM{$i}
,element COL_NAME{$r/name()}
,element COL_VALUE{$r/text()}
}’
passing dbms_xmlgen.getxmltype(
q'[
@tmp2.sql
]’
)
columns
row_num int
,col_name varchar2(30)
,col_value varchar2(100)
);
— disabling pause and breaks:
set pause off
clear breaks
@settings.sql
[/sourcecode]
Example:
[sourcecode language=”sql”]
SQL> select * from hr.employees where rownum<3;
EMPLOYEE_ID FIRST_NAME LAST_NAME EMAIL PHONE_NUMBER HIRE_DATE JOB_ID SALARY COMMISSION_PCT MANAGER_ID DEPARTMENT_ID
———– ——————– ————————- ————————- ——————– ——— ———- ———- ————– ———- ————-
198 Donald OConnell DOCONNEL 650.507.9833 21-JUN-07 SH_CLERK 2600 124 50
199 Douglas Grant DGRANT 650.507.9844 13-JAN-08 SH_CLERK 2600 124 50
Elapsed: 00:00:00.01
SQL> @print_last
Wrote file settings.sql
Wrote file tmp.sql
ROW_NUM COL_NAME COL_VALUE
———- —————————— —————————————————————————————————-
1 EMPLOYEE_ID 198
FIRST_NAME Donald
LAST_NAME OConnell
EMAIL DOCONNEL
PHONE_NUMBER 650.507.9833
HIRE_DATE 21-JUN-07
JOB_ID SH_CLERK
SALARY 2600
MANAGER_ID 124
DEPARTMENT_ID 50
Press Enter to view next row…
[/sourcecode]
PS. if you will use xmltype(cursor(…)) on versions less that 11.2.0.3 you can get errors with xml rewriting. In this case you need to disable it:
alter session set events '19027 trace name context forever, level 0x1';
Update:
Vladimir Przyjalkowski rightly pointed out that such approach will be suboptimal in case of big amount of data:
A nice toy, but i’m sure it will not tolerate big data.
It is absolutely true, because at first, “xmltype(cursor(…))” aggregated data as xmltype, and only then xmltable returns data.
But I use print_table for small amount of data only, and in case of when i want to see sample of data, i usually add limitation by rownum, which also convenient because it automatically changes optimizer mode with enabled parameter “_optimizer_rownum_pred_based_fkr” (it is default):
SQL> @param_ rownum NAME VALUE DEFLT TYPE DESCRIPTION ---------------------------------- ------- ------ -------- ------------------------------------------------------ _optimizer_rownum_bind_default 10 TRUE number Default value to use for rownum bind _optimizer_rownum_pred_based_fkr TRUE TRUE boolean enable the use of first K rows due to rownum predicate _px_rownum_pd TRUE TRUE boolean turn off/on parallel rownum pushdown optimization
However, we can easily change the our query to make it optimally with a lot of data too:
select row_num
,t2.*
from
(select rownum row_num
, column_value x
from table(xmlsequence(cursor( &1 )))
) t1
,xmltable( '/ROW/*'
passing t1.x
columns
col_num for ordinality
,col_name varchar2(30) path 'name()'
,col_value varchar2(100) path '.'
)(+) t2;
Lets test it with pipelined function which will pipe rows infinitely and log count of fetched rows:
-- drop table xt_log purge;
-- drop function f_infinite;
create table xt_log(n int);
create function f_infinite
return sys.ku$_objnumset pipelined
as
i int:=0;
pragma autonomous_transaction;
begin
loop
i:=i+1;
insert into xt_log values(i);
commit;
pipe row(i);
end loop;
exception
when NO_DATA_NEEDED then
commit;
end;
/
[sourcecode language=”sql”]
— set arraysize for minimal value, so sqlplus did not fetch extra rows:
set arraysize 2
— show output
set termout on
— but without echo
set echo off
— without newpage on start:
set embedded on
— scrolling control
set pause on
— two lines between rows:
set newpage 2
— text for prompt after each page:
set pause "Press Enter to view next row…"
— new page on new "row_num"
break on row_num skip page
— main query:
select row_num
,t2.*
from
(select rownum row_num
, column_value x
from table(xmlsequence(cursor( &1 )))
) t1
,xmltable( ‘/ROW/*’
passing t1.x
columns
col_num for ordinality
,col_name varchar2(30) path ‘name()’
,col_value varchar2(100) path ‘.’
)(+) t2;
— disabling pause and breaks:
set pause off
clear breaks
[/sourcecode]
And look final test:
SQL> select * from xt_log;
no rows selected
SQL> @print_table2 "select * from table(f_infinite)"
Press Enter to view next row...
ROW_NUM COL_NUM COL_NAME COL_VALUE
---------- ---------- ------------------------------ -----------
1 1 COLUMN_VALUE 1
Press Enter to view next row...
ROW_NUM COL_NUM COL_NAME COL_VALUE
---------- ---------- ------------------------------ -----------
2 1 COLUMN_VALUE 2
Press Enter to view next row...
ROW_NUM COL_NUM COL_NAME COL_VALUE
---------- ---------- ------------------------------ -----------
3 1 COLUMN_VALUE 3
Press Enter to view next row...
ROW_NUM COL_NUM COL_NAME COL_VALUE
---------- ---------- ------------------------------ -----------
4 1 COLUMN_VALUE 4
Press Enter to view next row...
ROW_NUM COL_NUM COL_NAME COL_VALUE
5 1 COLUMN_VALUE 5
Press Enter to view next row...
6 rows selected.
-------------------------------
SQL> select * from xt_log;
N
----------
1
2
3
4
5
6
7
7 rows selected.
So we got what we wanted!
PS. Full scripts:
1. Simple: print_table.sql
2. For big queries: print_table2.sql