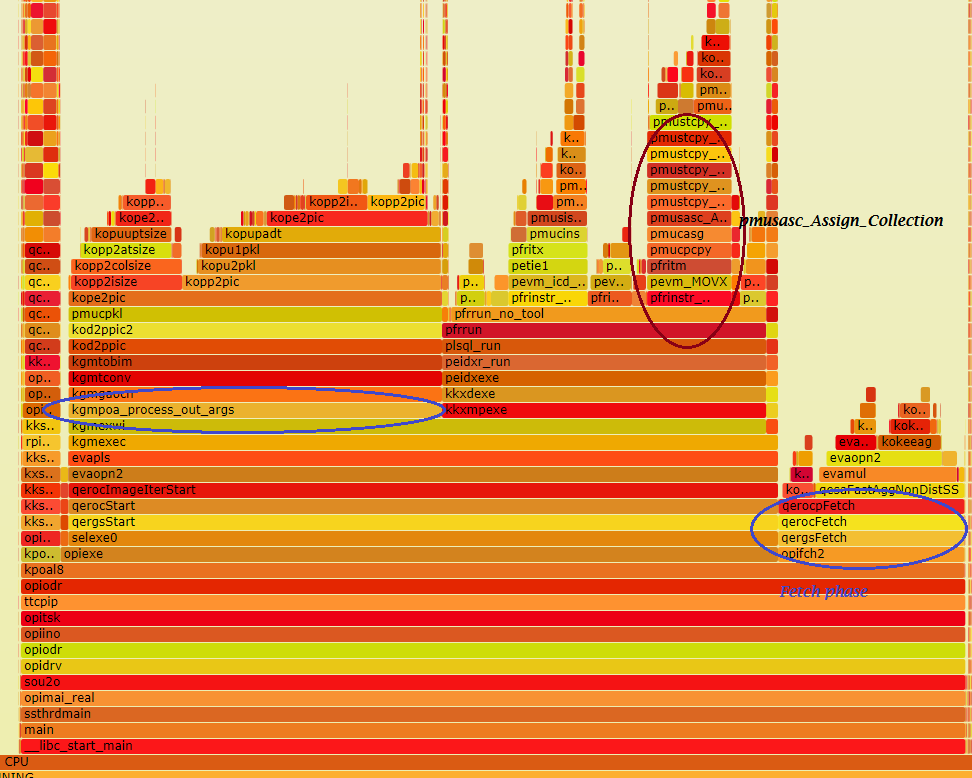
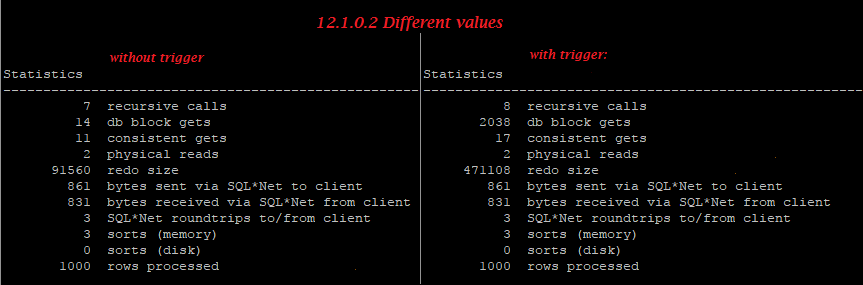
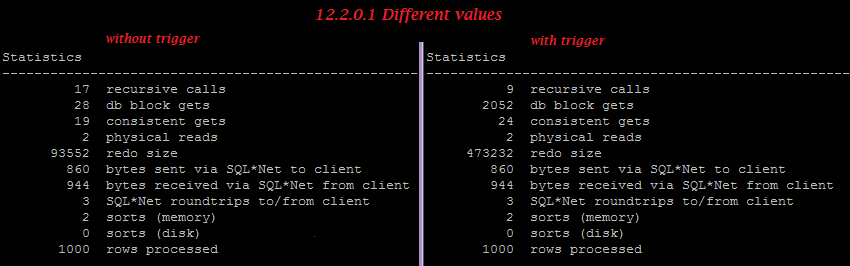
I was looking through a test script and saw something I didn’t know you could do in Oracle. I mentioned it to an Oracle ACE and he didn’t know it either. I then said to the External Table engineers “Oh I see you’ve added this cool new feature” and he replied dryly – “Yes, we added it in Oracle 10.1”. Ouch! So just in case you also didn’t know, you can create an External Table using a CTAS and the ORACLE_DATAPUMP driver.
This feature only work with the ORACLE_DATAPUMP access driver (it does NOT work with with the LOADER, HIVE, or HDFS drivers) and we can use it like this:
SQL> create table cet_test organization external
2 (
3 type ORACLE_DATAPUMP
4 default directory T_WORK
5 location ('xt_test01.dmp','xt_test02.dmp')
6 ) parallel 2
7 as select * from lineitem
Table created.
Checking the results shows us
-rw-rw---- ... 786554880 Mar 9 10:48 xt_test01.dmp
-rw-rw---- ... 760041472 Mar 9 10:48 xt_test02.dmp
This can be a great way of creating a (redacted) sample of data to give to a developer to test or for a bug repro to give to support or to move between systems.