One of the easiest ways is to use diagnostic events:
alter session set events 'sql_trace {callstack: fname xctend} errorstack(1)';
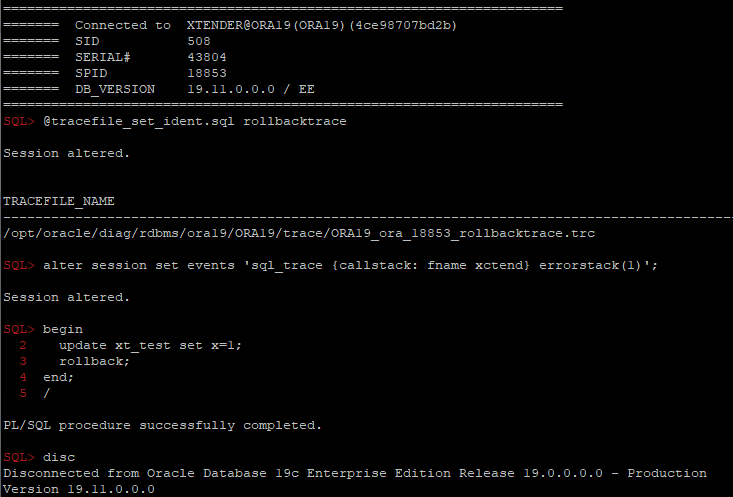
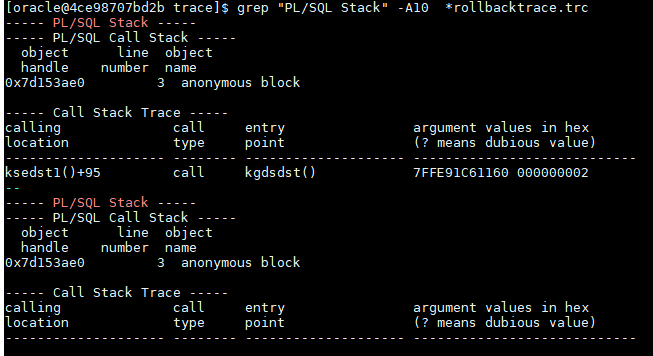

One of the easiest ways is to use diagnostic events:
alter session set events 'sql_trace {callstack: fname xctend} errorstack(1)';
I know 2 “special” exceptions that can’t be processed in exception handler:
Tanel Poder described the first one (ORA-01013) in details here: https://tanelpoder.com/2010/02/17/how-to-cancel-a-query-running-in-another-session/ where Tanel shows that this error is based on SIGURG signal (kill -URG):
-- 1013 will not be caught:
declare
e exception;
pragma exception_init(e,-1013);
begin
raise e;
exception when others then dbms_output.put_line('caught');
end;
/
declare
*
ERROR at line 1:
ORA-01013: user requested cancel of current operation
ORA-06512: at line 5
Got an interesting question today in RuOUG:
Some very simple PL/SQL procedures usually are completed within ~50ms, but sometimes sporadically longer than a second. For example, the easiest one from these procedures:
create or replace PROCEDURE XXXX (
P_ORG_NUM IN number,
p_result OUT varchar2,
p_seq OUT number
) AS
BEGIN
p_seq := P_ORG_NUM; p_result:='';
END;
sql_trace shows that it was executed for 1.001sec and all the time was “ON CPU”:
Continue readingAlex R recently discovered interesting thing: in SQL pipelined functions work much faster than simple non-pipelined table functions, so if you already have simple non-pipelined table function and want to get its results in sql (select * from table(fff)), it’s much better to create another pipelined function which will get and return its results through PIPE ROW().
A bit more details:
Assume we need to return collection “RESULT” from PL/SQL function into SQL query “select * from table(function_F(…))”.
If we create 2 similar functions: pipelined f_pipe and simple non-pipelined f_non_pipe,
create or replace function f_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
begin
...
for i in 1..n loop
pipe row (result(i));
end loop;
end f_pipe;
/
create or replace function f_non_pipe(n int) return tt_id_value
as
result tt_id_value;
begin
...
return result;
end f_non_pipe;
/
[sourcecode language=”sql”]
create or replace type to_id_value as object (id int, value int)
/
create or replace type tt_id_value as table of to_id_value
/
create or replace function f_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
for i in 1..n loop
pipe row (result(i));
end loop;
end f_pipe;
/
create or replace function f_non_pipe(n int) return tt_id_value
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
return result;
end f_non_pipe;
/
create or replace function f_pipe_for_nonpipe(n int) return tt_id_value pipelined
as
result tt_id_value;
begin
result:=f_non_pipe(n);
for i in 1..result.count loop
pipe row (result(i));
end loop;
end;
/
create or replace function f_udf_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
for i in 1..n loop
pipe row (result(i));
end loop;
end;
/
create or replace function f_udf_non_pipe(n int) return tt_id_value
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
return result;
end;
/
[/sourcecode]
[sourcecode language=”sql”]
set echo on feed only timing on;
–alter session set optimizer_adaptive_plans=false;
–alter session set "_optimizer_use_feedback"=false;
select sum(id * value) s from table(f_pipe(&1));
select sum(id * value) s from table(f_non_pipe(&1));
select sum(id * value) s from table(f_pipe_for_nonpipe(&1));
select sum(id * value) s from table(f_udf_pipe(&1));
select sum(id * value) s from table(f_udf_non_pipe(&1));
with function f_inline_non_pipe(n int) return tt_id_value
as
result tt_id_value;
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
return result;
end;
select sum(id * value) s from table(f_inline_non_pipe(&1));
/
set timing off echo off feed on;
[/sourcecode]
| Function | 1 000 000 elements | 100 000 elements |
|---|---|---|
| F_PIPE | 2.46 | 0.20 |
| F_NON_PIPE | 4.39 | 0.44 |
| F_PIPE_FOR_NONPIPE | 2.61 | 0.26 |
| F_UDF_PIPE | 2.06 | 0.20 |
| F_UDF_NON_PIPE | 4.46 | 0.44 |
I was really surprised that even “COLLECTION ITERATOR PICKLER FETCH” with F_PIPE_FOR_NONPIPE that gets result of F_NON_PIPE and returns it through PIPE ROW() works almost twice faster than F_NON_PIPE, so I decided to analyze it using stapflame by Frits Hoogland.
I added “dbms_lock.sleep(1)” into both of these function after collection generation, to compare the difference only between “pipe row” in loop and “return result”:
[sourcecode language=”sql”]
create or replace function f_pipe(n int) return tt_id_value pipelined
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
dbms_lock.sleep(1);
for i in 1..n loop
pipe row (result(i));
end loop;
end f_pipe;
/
create or replace function f_non_pipe(n int) return tt_id_value
as
result tt_id_value;
procedure gen is
begin
result:=tt_id_value();
result.extend(n);
for i in 1..n loop
result(i):=to_id_value(i, 1);
end loop;
end;
begin
gen();
dbms_lock.sleep(1);
return result;
end f_non_pipe;
/
[/sourcecode]
And stapflame showed that almost all overhead was consumed by the function “kgmpoa_Assign_Out_Arguments”:
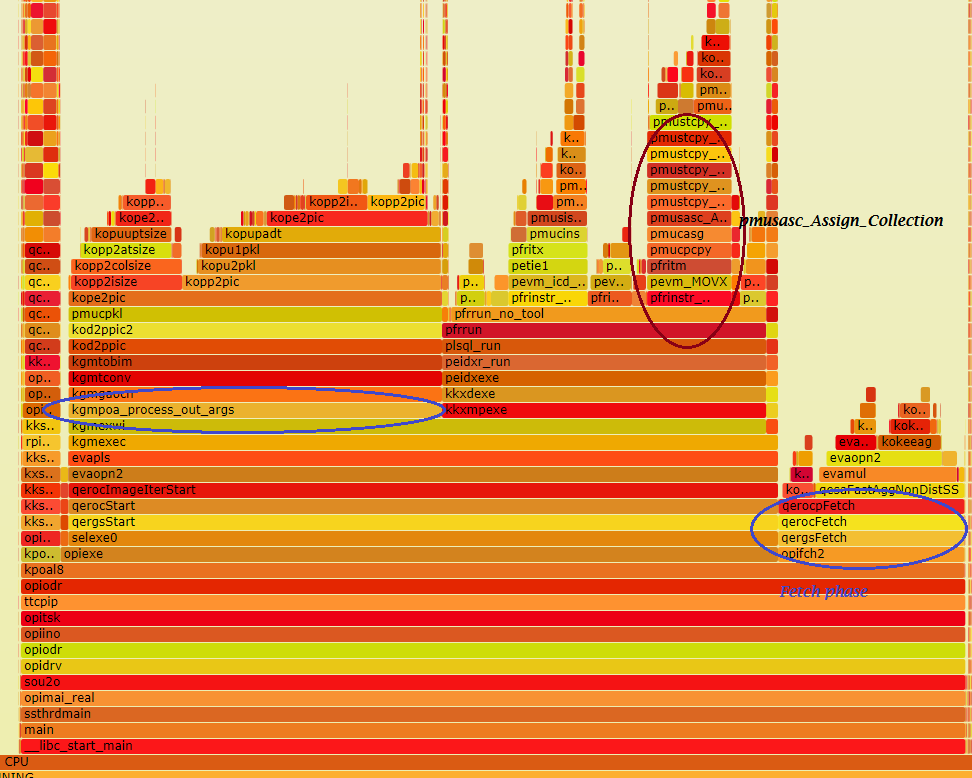
I don’t know what this function is doing exactly, but we can see that oracle assign collection a bit later.
From other functions in this stack(pmucpkl, kopp2isize, kopp2colsize, kopp2atsize(attribute?), kopuadt) I suspect that is some type of preprocessiong of return arguments.
What do you think about it?
Full stapflame output:
stapflame_nonpipe
stapflame_pipe
This interesting question was posted on our russian forum yesterday:
We have a huge PL/SQL package and this simple function returns wrong result when it’s located at the end of package body:
create or replace package body PKGXXX as ... function ffff return number is nRes number; begin nRes := 268435456; return nRes; end; end; /But it works fine in any of the following cases:
* replace 268435456 with power(2, 28), or
* replace 268435456 with small literal like 268, or
* move this function to the beginning of package body
The one of the interesting findings was that the returned value is equal to the one of literals in another function.
We can reproduce this bug even with an anonymous pl/sql block. The following test case uses 32768 integer literals from 1000001 to 1032768 and prints 5 other integers:
declare n number;
begin
n:=1000001; -- this part
n:=1000002; -- creates
n:=1000003; -- 32768
... -- integer
n:=1032768; -- literals
dbms_output.put_line('100000='||100000); -- it should print: 100000=100000
dbms_output.put_line('32766 ='||32766);
dbms_output.put_line('32767 ='||32767);
dbms_output.put_line('32768 ='||32768);
dbms_output.put_line('32769 ='||32769);
end;
[sourcecode language=”sql”]
declare
c clob:=’declare n number;begin’||chr(10);
f varchar2(100):=’n:=%s;’||chr(10);
v varchar2(32767);
n number:=32768;
begin
for i in 1..n loop
v:=v||utl_lms.format_message(f,to_char(1e7+i));
if length(v)>30000 then
c:=c||v;
v:=”;
end if;
end loop;
v:=v||q'[
dbms_output.put_line(‘100000=’||100000);
dbms_output.put_line(‘32766 =’||32766);
dbms_output.put_line(‘32767 =’||32767);
dbms_output.put_line(‘32768 =’||32768);
dbms_output.put_line(‘32769 =’||32769);
end;
]’;
c:=c||v;
execute immediate c;
end;
/
[/sourcecode]
100000=10000001 32766 =32766 32767 =32767 32768 =10000002 32769 =10000003
This test case well demonstrates wrong results:
* instead of 100000 we get 10000001, which is the value from first line after “begin”, ie 1st integer literal in the code,
* for 32766 and 32767 oracle returns right values
* instead of 32768 (==32767+1) it returns 10000002, which is the integer from 2nd line, ie 2nd integer literal in the code,
* instead of 32769 (==32767+2) it returns 10000003, which is the integer from 3rd line, ie 3rd integer literal in the code
After several tests I can make a conclusion:
So we can describe this behaviour using first test case:
declare n number;
begin
n:=1000001; -- this part
n:=1000002; -- creates
n:=1000003; -- 32768
... -- integer
n:=1032768; -- literals
dbms_output.put_line('100000='||100000); -- it should print 100000, ie 32768th element of array, but prints 10000001
-- where 10000001 is the 1st element of array (1==mod(32768,32767))
dbms_output.put_line('32766 ='||32766); -- these 2 lines print right values,
dbms_output.put_line('32767 ='||32767); -- because their values are in the range of -32768..32767
dbms_output.put_line('32768 ='||32768); -- this line contains 32769th element and prints 2nd element of array (2==mod(32769,32767))
dbms_output.put_line('32769 ='||32769); -- this line contains 32770th element and prints 3nd element of array (3==mod(32770,32767))
end;
The following query can help you to find objects which can potentially have this problem:
select
s.owner,s.name,s.type
,sum(regexp_count(text,'(\W|^)3\d{4,}([^.0-9]|$)')) nums_count -- this regexp counts integer literals >= 30000
from dba_source s
where
owner='&owner'
and type in ('FUNCTION','PROCEDURE','PACKAGE','PACKAGE BODY')
group by s.owner,s.name,s.type
having sum(regexp_count(text,'(\W|^)3\d{4,}([^.0-9]|$)'))>32767 -- filter only objects which have >=32767 integer literal
Workaround:
You may noticed that I wrote about INTEGER literals only, so the easiest workaround is to make them FLOAT – just add “.” to the end of each literal:
declare n number;
begin
n:=1000001.;
n:=1000002.;
n:=1000003.;
...
n:=1032768.;
dbms_output.put_line('100000='||100000.);
dbms_output.put_line('32766 ='||32766.);
dbms_output.put_line('32767 ='||32767.);
dbms_output.put_line('32768 ='||32768.);
dbms_output.put_line('32769 ='||32769.);
end;
[sourcecode language=”sql”]
declare
c clob:=’declare n number;begin’||chr(10);
f varchar2(100):=’n:=%s.;’||chr(10); — I’ve added here "."
v varchar2(32767);
n number:=32768;
begin
for i in 1..n loop
v:=v||utl_lms.format_message(f,to_char(1e7+i));
if length(v)>30000 then
c:=c||v;
v:=”;
end if;
end loop;
v:=v||q'[
dbms_output.put_line(‘100000=’||100000.); — .
dbms_output.put_line(‘32766 =’||32766.);
dbms_output.put_line(‘32767 =’||32767.);
dbms_output.put_line(‘32768 =’||32768.);
dbms_output.put_line(‘32769 =’||32769.);
end;
]’;
c:=c||v;
execute immediate c;
end;
/
[/sourcecode]
In previous posts about caching mechanism of determinstic functions I wrote that cached results are kept only between fetch calls, but there is one exception from this rule: if all function parameters are literals, cached result will not be flushed every fetch call.
Little example with difference:
SQL> create or replace function f_deterministic(p varchar2)
2 return varchar2
3 deterministic
4 as
5 begin
6 dbms_output.put_line(p);
7 return p;
8 end;
9 /
SQL> set arrays 2 feed on;
SQL> set serverout on;
SQL> select
2 f_deterministic(x) a
3 ,f_deterministic('literal') b
4 from (select 'not literal' x
5 from dual
6 connect by level<=10
7 );
A B
------------------------------ ------------------------------
not literal literal
not literal literal
not literal literal
not literal literal
not literal literal
not literal literal
not literal literal
not literal literal
not literal literal
not literal literal
10 rows selected.
not literal
literal
not literal
not literal
not literal
not literal
not literal
As you can see, ‘literal’ was printed once, but ‘not literal’ was printed 6 times, so it was returned from cache 4 times.
Also i want to show the differences in consistency between:
1. Calling a function with determinstic and result_cache;
2. Calling an operator for function with result_cache;
3. Calling an operator for function with deterministic and result_cache;
In this example I will do updates in autonomouse transactions to emulate updates in another session during query execution:
[sourcecode language=”sql”]
drop table t1 purge;
drop table t2 purge;
drop table t3 purge;
create table t1 as select 1 id from dual;
create table t2 as select 1 id from dual;
create table t3 as select 1 id from dual;
create or replace procedure p1_update as
pragma autonomous_transaction;
begin
update t1 set id=id+1;
commit;
end;
/
create or replace procedure p2_update as
pragma autonomous_transaction;
begin
update t2 set id=id+1;
commit;
end;
/
create or replace procedure p3_update as
pragma autonomous_transaction;
begin
update t3 set id=id+1;
commit;
end;
/
[/sourcecode]
[sourcecode language=”sql”]
create or replace function f1(x varchar2) return number result_cache deterministic
as
r number;
begin
select id into r from t1;
p1_update;
return r;
end;
/
[/sourcecode]
[sourcecode language=”sql”]
create or replace function f2(x varchar2) return number result_cache
as
r number;
begin
select id into r from t2;
p2_update;
return r;
end;
/
create or replace operator o2
binding(varchar2)
return number
using f2
/
[/sourcecode]
[sourcecode language=”sql”]
create or replace function f3(x varchar2) return number result_cache deterministic
as
r number;
begin
select id into r from t3;
p3_update;
return r;
end;
/
create or replace operator o3
binding(varchar2)
return number
using f3
/
[/sourcecode]
SQL> set arrays 2;
SQL> select
2 f1(dummy) variant1
3 ,o2(dummy) variant2
4 ,o3(dummy) variant3
5 from dual
6 connect by level<=10;
VARIANT1 VARIANT2 VARIANT3
---------- ---------- ----------
1 1 1
2 1 1
2 1 1
3 1 1
3 1 1
4 1 1
4 1 1
5 1 1
5 1 1
6 1 1
10 rows selected.
SQL> /
VARIANT1 VARIANT2 VARIANT3
---------- ---------- ----------
7 11 11
8 11 11
8 11 11
9 11 11
9 11 11
10 11 11
10 11 11
11 11 11
11 11 11
12 11 11
10 rows selected.
We can see that function F1 returns same results every 2 execution – it is equal to fetch size(“set arraysize 2”),
operator O2 and O3 return same results for all rows in first query execution, but in the second query executions we can see that they are incremented by 10 – it’s equal to number of rows.
What we can learn from that:
1. The use of the function F1 with result_cache and deterministic reduces function executions, but all function results are inconsistent with query;
2. Operator O2 returns consistent results, but function is always executed because we invalidating result_cache every execution;
3. Operator O3 works as well as operator O2, without considering that function is deterministic.
All tests scripts: tests.zip
Craig Shallahamer wrote excellent article “When is v$sesstat really updated?”.
And my today post just a little addition and correction about the difference of updating ‘Db time’ and ‘CPU used by this session’ statistics.
In this test I want to show that the statistics will be updated after every fetch call.
I have set arraysize=2, so sql*plus will fetch by 2 rows:
(full script)
-- Result will be fetched by 2 rows:
set arraysize 2;
-- this query generates CPU consumption
-- in the scalar subquery on fetch phase,
-- so CPU consumption will be separated
-- into several periods between fetch calls:
with gen as (
select/*+ materialize */
level n, lpad(level,400) padding
from dual
connect by level<=200
)
,stat as (
select/*+ inline */
sid,name,value
from v$mystat st, v$statname sn
where st.statistic#=sn.statistic#
and sn.name in ('DB time'
,'CPU used by this session'
,'user calls'
,'recursive calls')
)
--first rows just for avoiding SQL*Plus effect with fetching 1 row at start,
-- others will be fetched by "arraysize" rows:
select null rn,null cnt,null dbtime,null cpu,null user_calls, null recursive_calls from dual
union all -- main query:
select
rownum rn
,(select count(*) from gen g1, gen g2, gen g3 where g1.n>g2.n and g1.n*0=main.n*0) cnt
,(select value from stat where sid*0=n*0 and name = 'DB time' ) dbtime
,(select value from stat where sid*0=n*0 and name = 'CPU used by this session' ) cpu
,(select value from stat where sid*0=n*0 and name = 'user calls' ) user_calls
,(select value from stat where sid*0=n*0 and name = 'recursive calls' ) recursive_calls
from gen main
where rownum<=10;
set arraysize 15;
Test results:
SQL> @tests/dbtime
RN CNT DBTIME CPU USER_CALLS RECURSIVE_CALLS
---------- ---------- ---------- ---------- ---------- ---------------
1 3980000 12021 11989 200 472
2 3980000 12021 11989 200 472
3 3980000 12121 12089 201 472
4 3980000 12121 12089 201 472
5 3980000 12220 12186 202 472
6 3980000 12220 12186 202 472
7 3980000 12317 12283 203 472
8 3980000 12317 12283 203 472
9 3980000 12417 12383 204 472
10 3980000 12417 12383 204 472
As you can see the statistics are updated after every fetch call.
Now since we already tested simple sql query, I want to do a little bit more complicated test with PL/SQL:
I’m going to write single PL/SQL block with next algorithm:
1. Saving stats
2. Executing some pl/sql code with CPU consumption
3. Getting statistics difference
4. Starting query from first test
5. Fetch 10 rows
6. Getting statistics difference
7. Fetch next 10 rows
8. Getting statistics difference
9. Fetch next 10 rows
10. Getting statistics difference
And after executing this block, i want to check statistics.
set feed off;
-- saving previous values
column st_dbtime new_value prev_dbtime noprint;
column st_cpu_time new_value prev_cputime noprint;
column st_user_calls new_value prev_user_calls noprint;
column st_recur_calls new_value prev_recur_calls noprint;
select max(decode(sn.NAME,'DB time' ,st.value))*10 st_dbtime
,max(decode(sn.NAME,'CPU used by this session' ,st.value))*10 st_cpu_time
,max(decode(sn.NAME,'user calls' ,st.value)) st_user_calls
,max(decode(sn.NAME,'recursive calls' ,st.value)) st_recur_calls
from v$mystat st, v$statname sn
where st.statistic#=sn.statistic#
and sn.name in ('DB time','CPU used by this session'
,'user calls','recursive calls'
)
/
-- variable for output from pl/sql block:
var output varchar2(4000);
prompt Executing test...;
----- main test:
declare
cnt int;
st_dbtime number;
st_cpu_time number;
st_user_calls number;
st_recur_calls number;
cursor c is
with gen as (select/*+ materialize */
level n, lpad(level,400) padding
from dual
connect by level<=200)
select
rownum rn
, (select count(*) from gen g1, gen g2, gen g3 where g1.n>g2.n and g1.n*0=main.n*0) cnt
from gen main
where rownum<=60;
type ctype is table of c%rowtype;
c_array ctype;
procedure SnapStats(descr varchar2:=null)
is
st_new_dbtime number;
st_new_cpu_time number;
st_new_user_calls number;
st_new_recur_calls number;
begin
select max(decode(sn.NAME,'DB time' ,st.value))*10 st_dbtime
,max(decode(sn.NAME,'CPU used by this session',st.value))*10 st_cpu_time
,max(decode(sn.NAME,'user calls' ,st.value)) st_user_calls
,max(decode(sn.NAME,'recursive calls' ,st.value)) st_recur_calls
into st_new_dbtime,st_new_cpu_time,st_new_user_calls,st_new_recur_calls
from v$mystat st, v$statname sn
where st.statistic#=sn.statistic#
and sn.name in ('DB time','CPU used by this session'
,'user calls','recursive calls'
);
if descr is not null then
:output:= :output || descr ||':'||chr(10)
|| 'sesstat dbtime: ' || (st_new_dbtime - st_dbtime )||chr(10)
|| 'sesstat cputime: ' || (st_new_cpu_time - st_cpu_time )||chr(10)
|| 'sesstat user calls: ' || (st_new_user_calls - st_user_calls )||chr(10)
|| 'sesstat recur calls:' || (st_new_recur_calls - st_recur_calls )||chr(10)
|| '======================================'||chr(10);
end if;
st_dbtime := st_new_dbtime ;
st_cpu_time := st_new_cpu_time ;
st_user_calls := st_new_user_calls ;
st_recur_calls := st_new_recur_calls;
end;
begin
-- saving previous stats:
SnapStats;
-- generating cpu load:
for i in 1..1e7 loop
cnt:=cnt**2+cnt**1.3-cnt**1.2;
end loop;
-- getting new stats:
SnapStats('After pl/sql loop');
open c;
SnapStats('After "open c"');
fetch c bulk collect into c_array limit 10;
SnapStats('After fetch 10 rows');
fetch c bulk collect into c_array limit 10;
SnapStats('After fetch 20 rows');
fetch c bulk collect into c_array limit 10;
SnapStats('After fetch 30 rows');
close c;
SnapStats('After close c');
end;
/
prompt 'Delta stats after statement(ms):';
select max(decode(sn.NAME,'DB time' ,st.value))*10
- &&prev_dbtime as delta_dbtime
,max(decode(sn.NAME,'CPU used by this session',st.value))*10
- &&prev_cputime as delta_cpu_time
,max(decode(sn.NAME,'user calls' ,st.value))
- &&prev_user_calls as delta_user_calls
,max(decode(sn.NAME,'recursive calls' ,st.value))
- &&prev_recur_calls as delta_recur_calls
from v$mystat st, v$statname sn
where st.statistic#=sn.statistic#
and sn.name in ('DB time','CPU used by this session'
,'user calls','recursive calls'
)
/
prompt 'Test results:';
col output format a40;
print output;
set feed off;
Output:
SQL> @tests/dbtime2
Executing test...
'Delta stats after statement(ms):'
DELTA_DBTIME DELTA_CPU_TIME DELTA_USER_CALLS DELTA_RECUR_CALLS
------------ -------------- ---------------- -----------------
18530 18460 5 33
Test results:
OUTPUT
----------------------------------------
After pl/sql loop:
sesstat dbtime: 0
sesstat cputime: 4350
sesstat user calls: 0
sesstat recur calls:2
======================================
After "open c":
sesstat dbtime: 0
sesstat cputime: 20
sesstat user calls: 0
sesstat recur calls:4
======================================
After fetch 10 rows:
sesstat dbtime: 0
sesstat cputime: 4680
sesstat user calls: 0
sesstat recur calls:2
======================================
After fetch 20 rows:
sesstat dbtime: 0
sesstat cputime: 4680
sesstat user calls: 0
sesstat recur calls:2
======================================
After fetch 30 rows:
sesstat dbtime: 0
sesstat cputime: 4690
sesstat user calls: 0
sesstat recur calls:2
======================================
After close c:
sesstat dbtime: 0
sesstat cputime: 0
sesstat user calls: 0
sesstat recur calls:3
======================================
We can notice that “CPU time” is updated at the same time as recursive calls, but “DB time” is updated only with “User calls”. Although this difference is not so important(because in most cases we can use other statistics in sum), but i think, if you want to instrument some code, it gives reason to check out desirable statistics for update time.
A little example:
Suppose we need to create a function, which would call some procedure:
create or replace procedure p_nested as a int; begin select 1 into a from dual where 1=0; end; / create or replace function f_no_data_found return varchar2 as begin p_nested; return 'ok'; end; /
When we call this function in PL/SQL, it will raise NO_DATA_FOUND and we will see it:
SQL> exec dbms_output.put_line(f_no_data_found); BEGIN dbms_output.put_line(f_no_data_found); END; * ERROR at line 1: ORA-01403: no data found ORA-06512: at "XTENDER.P_NESTED", line 4 ORA-06512: at "XTENDER.F_NO_DATA_FOUND", line 3 ORA-06512: at line 1
But it doesn’t when we call it in SQL, because it’s normal for SQL: it’s just like a result of scalar subquery that returns nothing – NULL:
SQL> set null "NUL" SQL> col ndf format a10 SQL> select f_no_data_found ndf from dual; NDF ---------- NUL 1 row selected.
So if you want the function to behave the same way in PL/SQL and SQL, just add exception handling with reraising another exception or just return null.
It must be at the level of reflexes – “select into” → “exception when no_data_found”
Otherwise, later, when code become a big and difficult, you can get unstable hidden error.
Let’s take a look at a very simple example:
[sourcecode language=”sql”]
SQL> create or replace function f_value_error return int is
2 begin
3 raise value_error;
4 return 1;
5 end;
6 /
Function created.
SQL> create or replace function f(i int:=f_value_error) return varchar2 is
2 begin
3 return ‘ok’;
4 exception when others then
5 return dbms_utility.format_error_backtrace;
6 end;
7 /
Function created.
SQL> set serverout on;
SQL> begin
2 dbms_output.put_line(‘From f: ‘||chr(10)||f);
3 dbms_output.put_line(‘****************************’);
4 exception when others then
5 dbms_output.put_line(‘****************************’);
6 dbms_output.put_line(‘From higher level:’||chr(10)||dbms_utility.format_error_backtrace);
7 dbms_output.put_line(‘****************************’);
8 end;
9 /
****************************
From higher level:
ORA-06512: at "XTENDER.F_VALUE_ERROR", line 3
ORA-06512: at line 2
****************************
PL/SQL procedure successfully completed.
[/sourcecode]
If the exception was caused in the declaration, we would see the “correct” backtrace, but exception would be still handled at higher level only:
[sourcecode language=”sql” highlight=”25″]
SQL> create or replace function f(i int:=null) return varchar2 is
2 l_i int:=nvl(i,f_value_error);
3 begin
4 return ‘ok’;
5 exception when others then
6 return dbms_utility.format_error_backtrace;
7 end;
8 /
Function created.
SQL> set serverout on;
SQL> begin
2 dbms_output.put_line(‘From f: ‘||chr(10)||f);
3 dbms_output.put_line(‘****************************’);
4 exception when others then
5 dbms_output.put_line(‘****************************’);
6 dbms_output.put_line(‘From higher level:’||chr(10)||dbms_utility.format_error_backtrace);
7 dbms_output.put_line(‘****************************’);
8 end;
9 /
****************************
From higher level:
ORA-06512: at "XTENDER.F_VALUE_ERROR", line 3
ORA-06512: at "XTENDER.F", line 2
ORA-06512: at line 2
****************************
PL/SQL procedure successfully completed.
[/sourcecode]
SQL> select PKG1.F(1,0,0,1275) from dual;
select PKG1.F(1,0,0,1275) from dual
*
ERROR at line 1:
ORA-06553: PLS-801: internal error [1401]
And the function has many functions calls in default parameters initialization, so I couldn’t even find out which one contains a root problem.