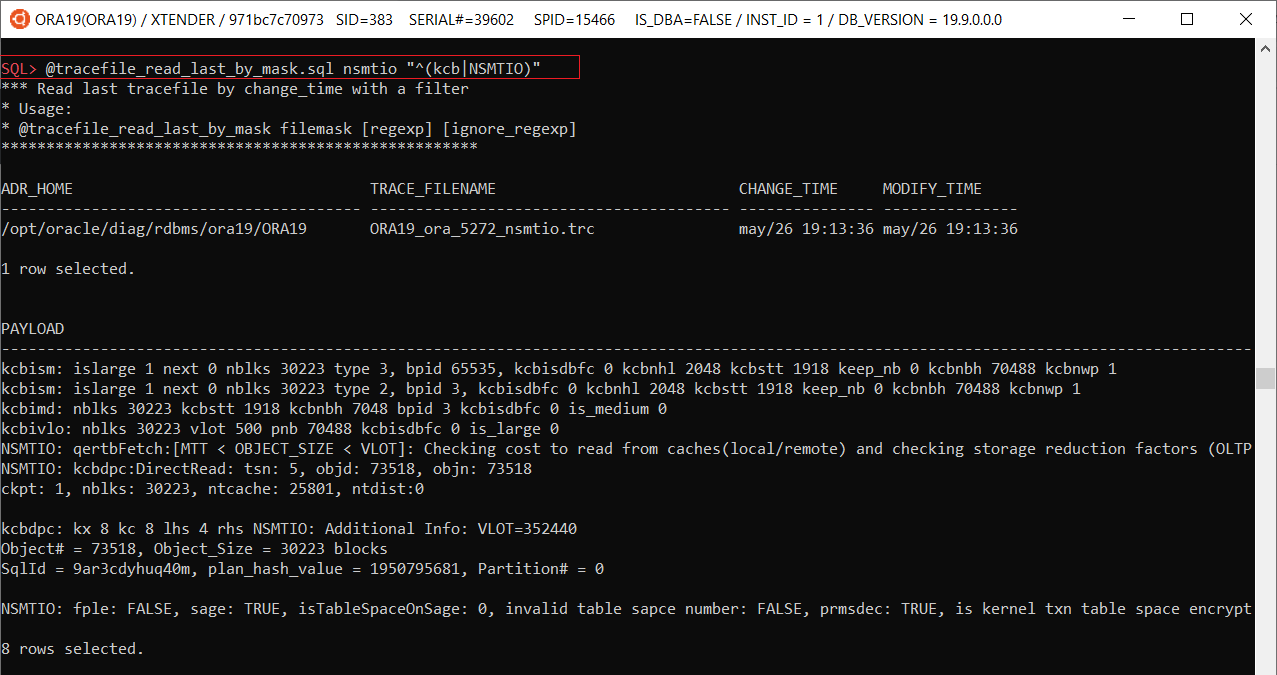
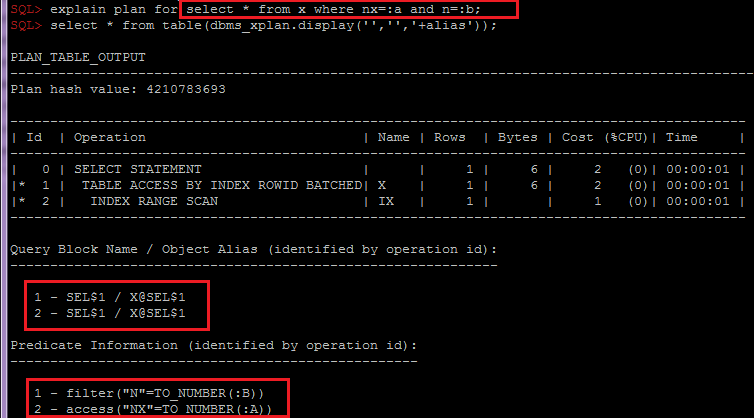
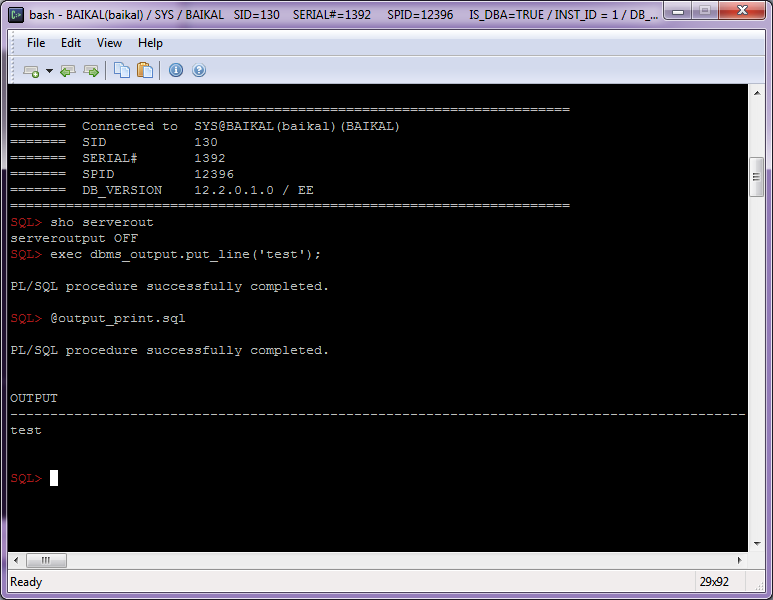
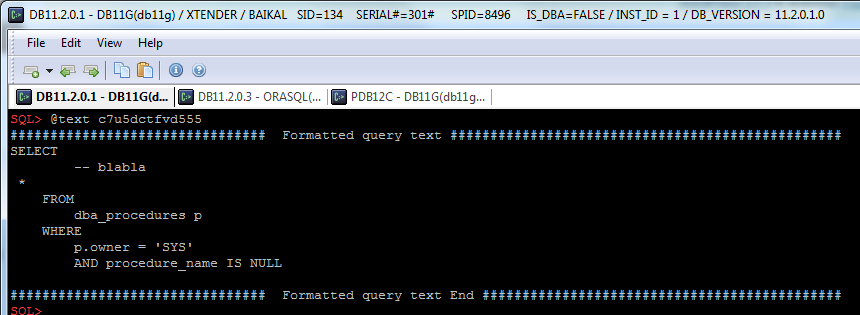
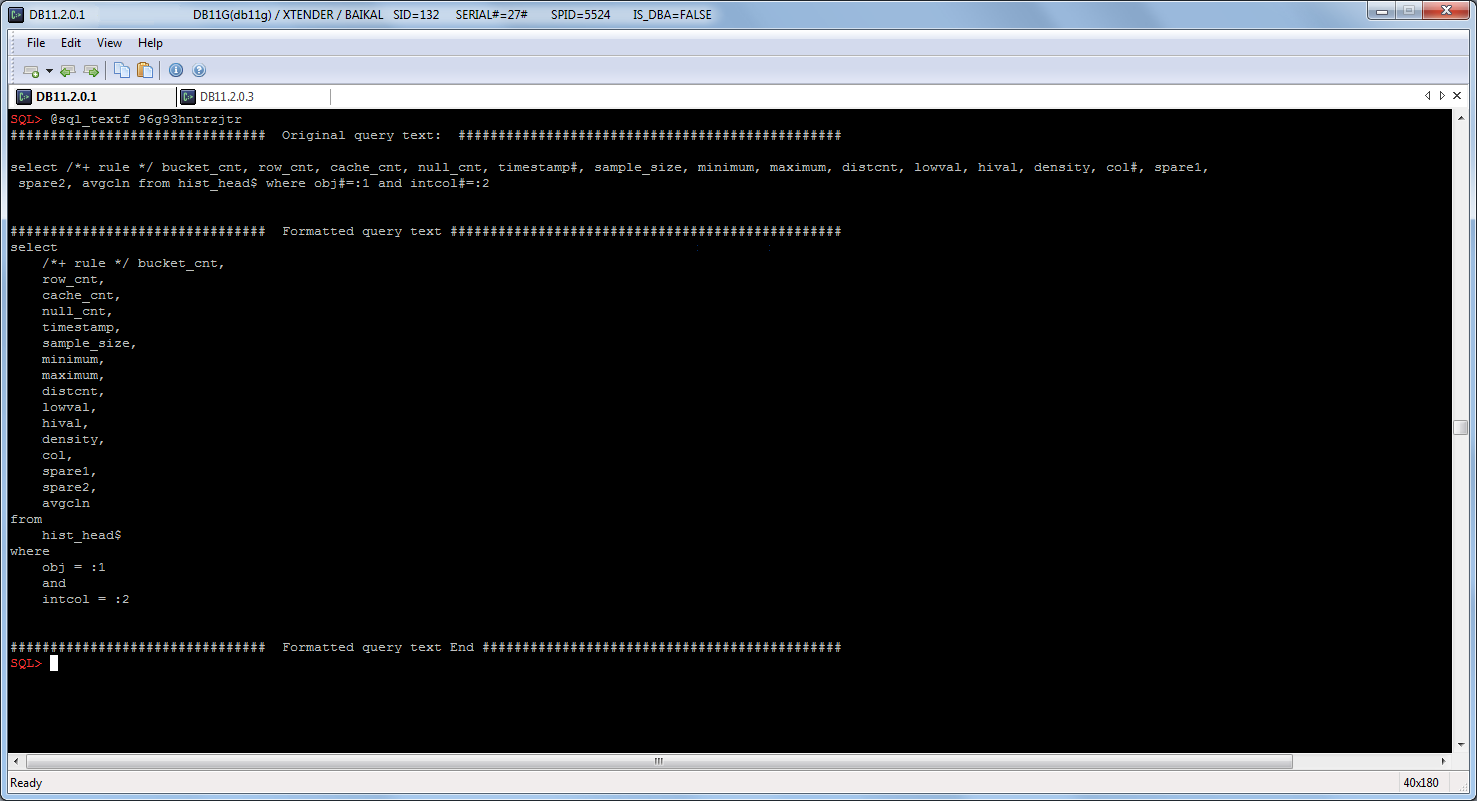
You may know that some applications generate queries with bind variables’ names like :1 or :”1″, and neither SQL*Plus nor SQLCl support such variables:
SQLPlus:
SQL> var 1 number;
SP2-0553: Illegal variable name "1".
SQLCL:
SQL> var 1 number;
ILLEGAL Variable Name "1"
So we can’t run such queries as-is, but, obviously, we can wrap them into anonymous PL/SQL blocks and even create a special script for that:
Continue reading