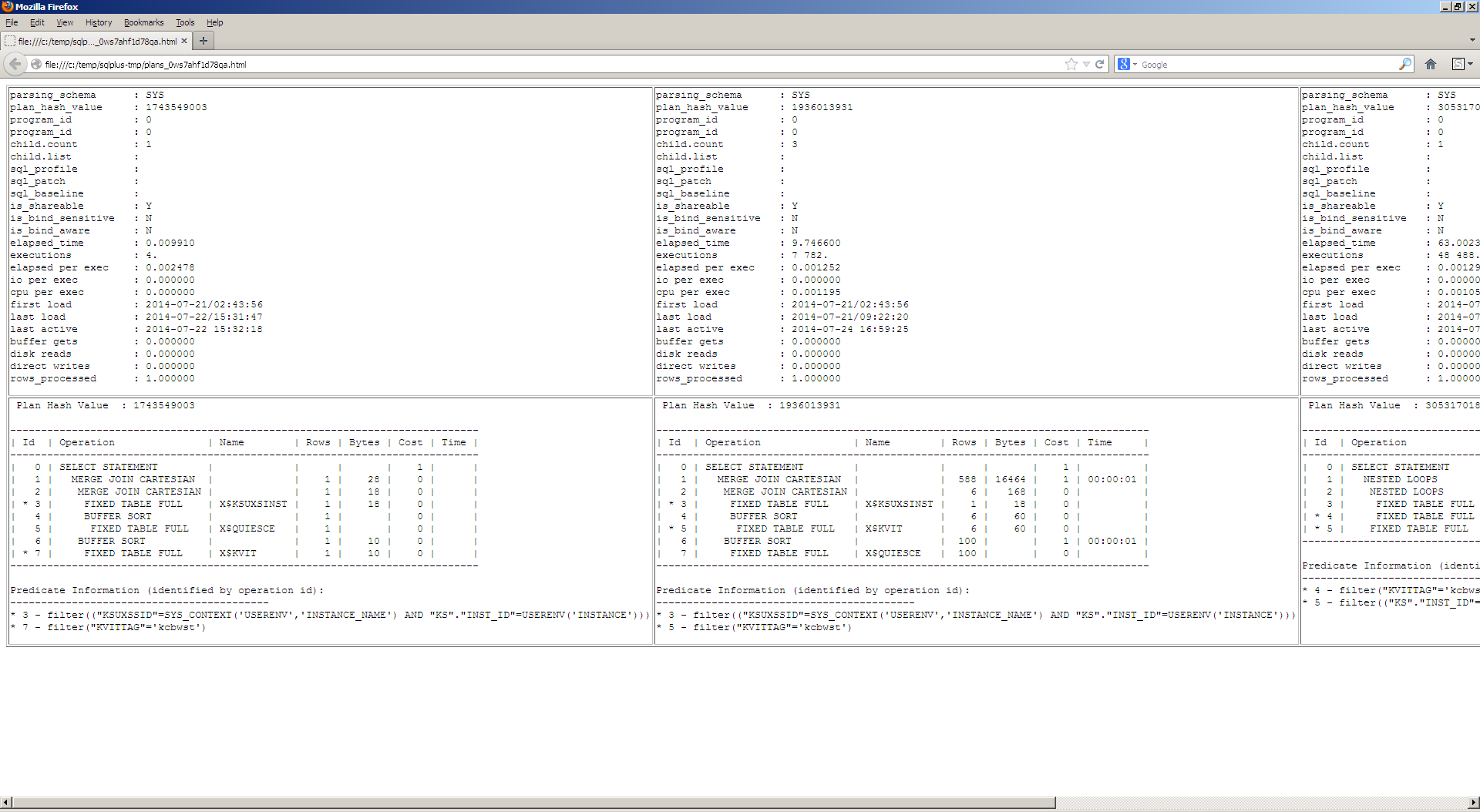
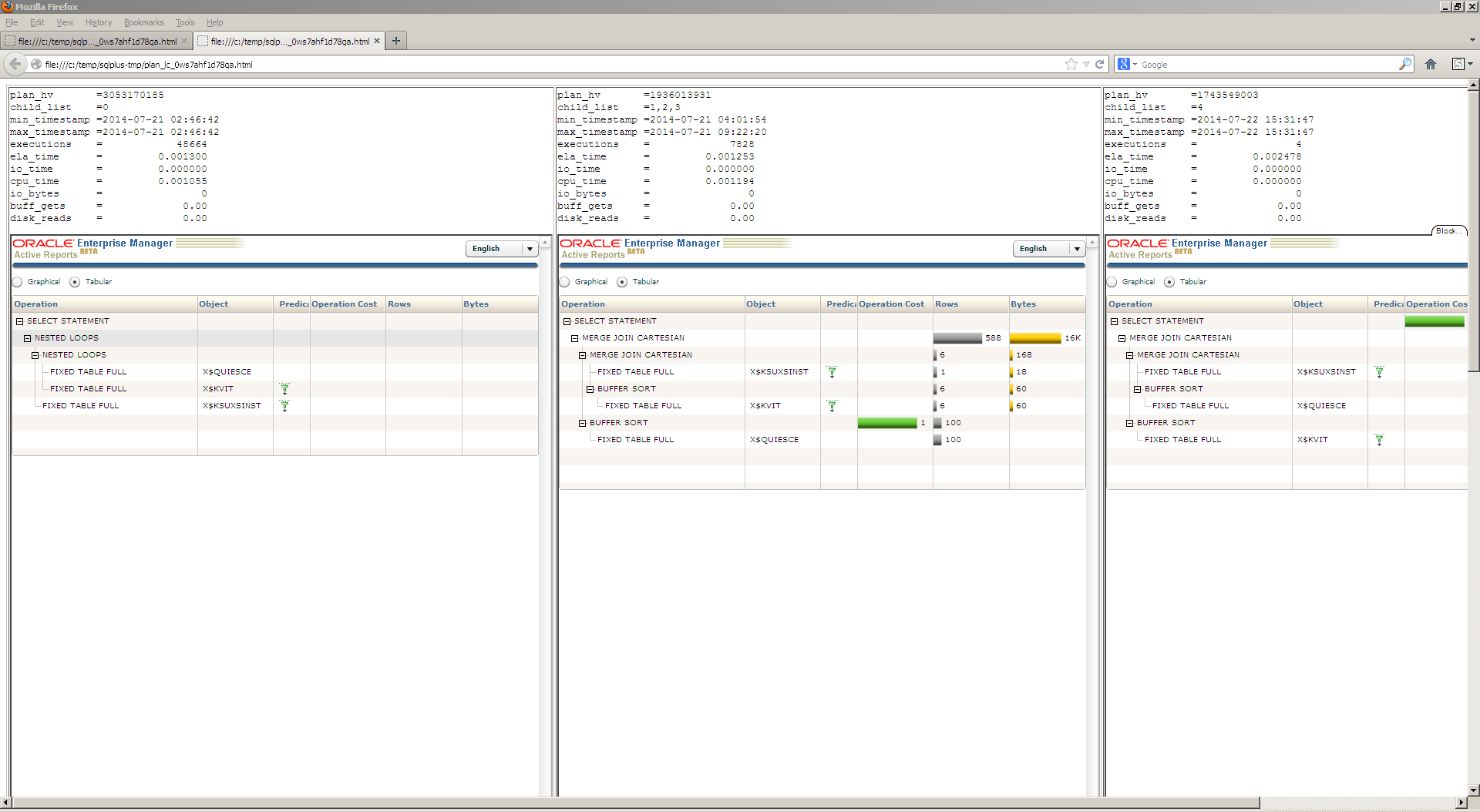
I’ve just found out that we can specify query block for PRECOMPUTE_SUBQUERY: /*+ precompute_subquery(@sel$2) */
So we can use it now with SQL profiles, SPM baselines and patches.
SQL> select/*+ precompute_subquery(@sel$2) */ * from dual where dummy in (select chr(level) from dual connect by level<=100);
D
-
X
SQL> @last
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID c437vsqj7c4jy, child number 0
-------------------------------------
select/*+ precompute_subquery(@sel$2) */ * from dual where dummy in
(select chr(level) from dual connect by level<=100)
Plan hash value: 272002086
---------------------------------------------------------------------------
| Id | Operation | Name | E-Rows |E-Bytes| Cost (%CPU)| E-Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 2 (100)| |
|* 1 | TABLE ACCESS FULL| DUAL | 1 | 2 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$1 / DUAL@SEL$1
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(("DUMMY"='' OR "DUMMY"='' OR "DUMMY"='♥' OR "DUMMY"='♦'
OR "DUMMY"='♣' OR "DUMMY"='♠' OR "DUMMY"='' OR "DUMMY"=' OR
"DUMMY"=' ' OR "DUMMY"=' ' OR "DUMMY"='' OR "DUMMY"='' OR "DUMMY"=' '
OR "DUMMY"='' OR "DUMMY"='' OR "DUMMY"='►' OR "DUMMY"='◄' OR
"DUMMY"='' OR "DUMMY"='' OR "DUMMY"='' OR "DUMMY"='' OR "DUMMY"=''
OR "DUMMY"='' OR "DUMMY"='↑' OR "DUMMY"='↓' OR "DUMMY"='' OR
"DUMMY"=' OR "DUMMY"='' OR "DUMMY"='' OR "DUMMY"='' OR "DUMMY"=''
OR "DUMMY"=' ' OR "DUMMY"='!' OR "DUMMY"='"' OR "DUMMY"='#' OR
"DUMMY"='$' OR "DUMMY"='%' OR "DUMMY"='&' OR "DUMMY"='''' OR
"DUMMY"='(' OR "DUMMY"=')' OR "DUMMY"='*' OR "DUMMY"='+' OR "DUMMY"=','
OR "DUMMY"='-' OR "DUMMY"='.' OR "DUMMY"='/' OR "DUMMY"='0' OR
"DUMMY"='1' OR "DUMMY"='2' OR "DUMMY"='3' OR "DUMMY"='4' OR "DUMMY"='5'
OR "DUMMY"='6' OR "DUMMY"='7' OR "DUMMY"='8' OR "DUMMY"='9' OR
"DUMMY"=':' OR "DUMMY"=';' OR "DUMMY"='<' OR "DUMMY"='=' OR "DUMMY"='>'
OR "DUMMY"='?' OR "DUMMY"='@' OR "DUMMY"='A' OR "DUMMY"='B' OR
"DUMMY"='C' OR "DUMMY"='D' OR "DUMMY"='E' OR "DUMMY"='F' OR "DUMMY"='G'
OR "DUMMY"='H' OR "DUMMY"='I' OR "DUMMY"='J' OR "DUMMY"='K' OR
"DUMMY"='L' OR "DUMMY"='M' OR "DUMMY"='N' OR "DUMMY"='O' OR "DUMMY"='P'
OR "DUMMY"='Q' OR "DUMMY"='R' OR "DUMMY"='S' OR "DUMMY"='T' OR
"DUMMY"='U' OR "DUMMY"='V' OR "DUMMY"='W' OR "DUMMY"='X' OR "DUMMY"='Y'
OR "DUMMY"='Z' OR "DUMMY"='[' OR "DUMMY"='\' OR "DUMMY"=']' OR
"DUMMY"='^' OR "DUMMY"='_' OR "DUMMY"='`' OR "DUMMY"='a' OR "DUMMY"='b'
OR "DUMMY"='c' OR "DUMMY"='d'))
PS. I’m not sure, but as far as i remember, when I tested it on 10.2, it didn’t work with specifying a query block.
And I have never seen such usage.