
I have a couple scripts for plans comparing:
1. https://github.com/xtender/xt_scripts/blob/master/diff_plans.sql
2. http://github.com/xtender/xt_scripts/blob/master/plans/diff_plans_active.sql
But they have dependencies on other scripts, so I decided to create a standalone script for more convenient use without the need to download other scripts and to set up the sql*plus environment.
I’ve tested it already with firefox, so you can try it now: http://github.com/xtender/xt_scripts/blob/master/plans/diff_plans_active_standalone.sql
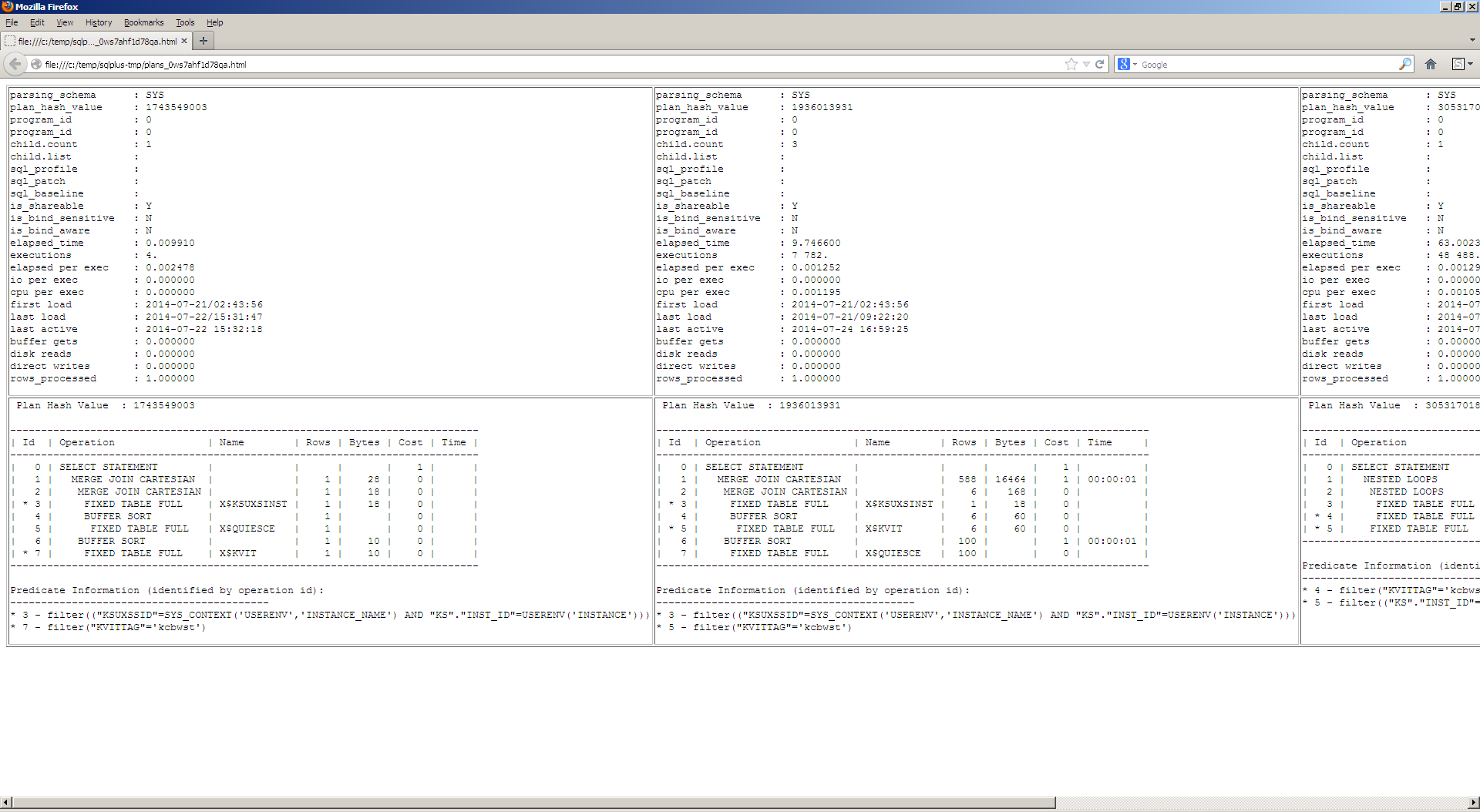
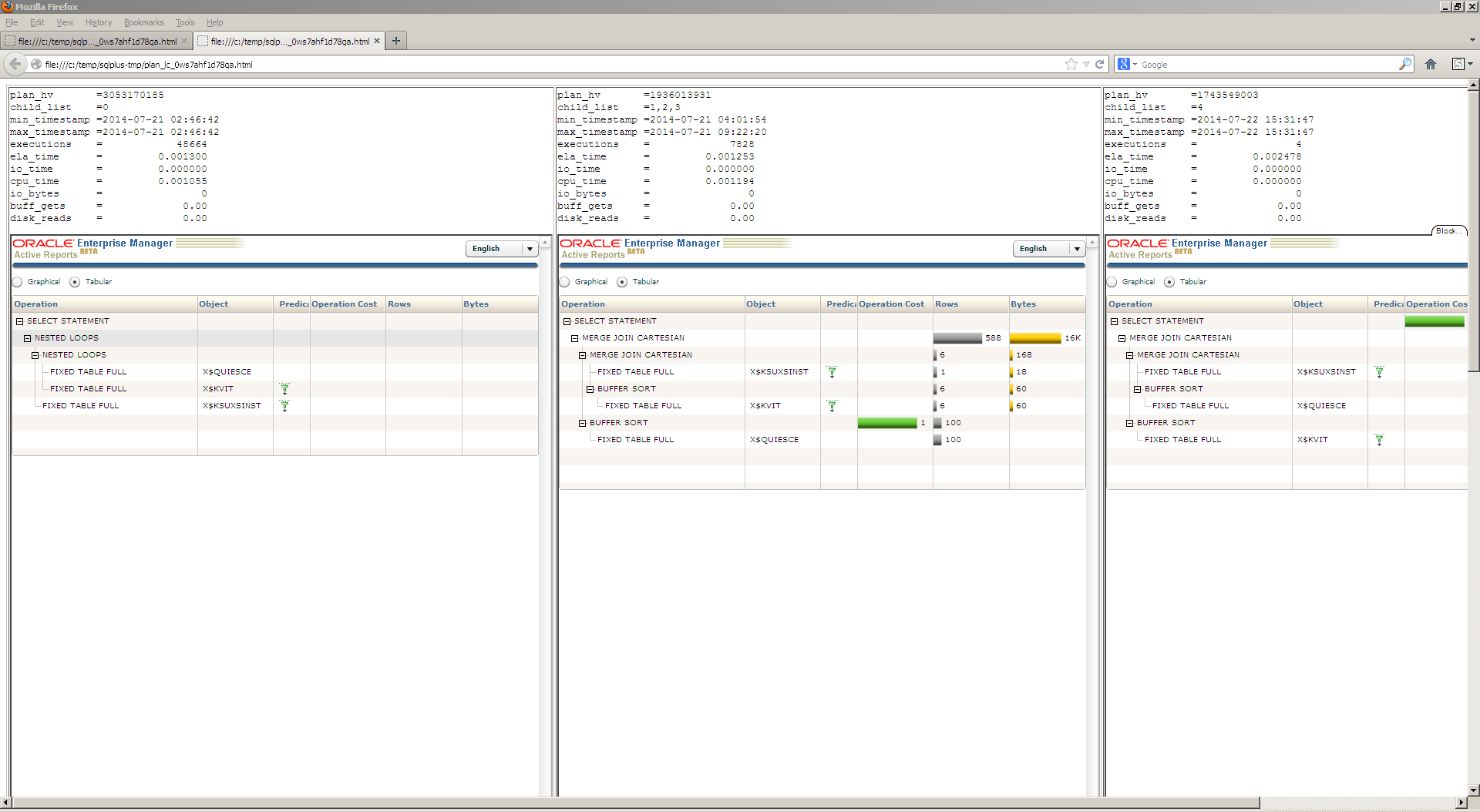
Some screenshots:
diff_plans.sql:
plans_active.sql:
Usage:
1. plans_active:
SQL> @plans_active 0ws7ahf1d78qa
2. diff_plans:
SQL> @diff_plans 0ws7ahf1d78qa *** Diff plans by sql_id. Version with package XT_PLANS. Usage: @plans/diff_plans2 sqlid [+awr] [-v$sql] P_AWR P_VSQL --------------- --------------- false true
Strictly speaking, we can do it sometimes easier: it’s quite simple to compare plans without first column “ID”, so we can simply compare “select .. from v$sql_plan/v$sql_plan_statistics_all/v$sql_plan_monitor” output with any comparing tool.