
Oracle 12c introduced Partial indexing, which works well for simple partitioned tables with literals. However, it has several significant issues:
Continue readingCategory Archives: bug
Laterals: is (+) documented for laterals?
I know this syntax for a long time, since when lateral() was not documented yet, but recently I found a bug: the following query successfully returns 1 row:
with a as (select level a from dual connect by level<10)
,b as (select 0 b from dual)
,c as (select 0 c from dual)
select
*
from a,
lateral(select * from b where a.a=b.b)(+) bb
--left outer join c on c.c=bb.b
where a=1;
A B
---------- ----------
1
But doesn’t if we uncomment “left join”:
with a as (select level a from dual connect by level<10)
,b as (select 0 b from dual)
,c as (select 0 c from dual)
select
*
from a,
lateral(select * from b where a.a=b.b)(+) bb
left outer join c on c.c=bb.b
where a=1;
no rows selected
And outer apply works fine:
with a as (select level a from dual connect by level<10)
,b as (select 0 b from dual)
,c as (select 0 c from dual)
select
*
from a
outer apply (select * from b where a.a=b.b) bb
left outer join c on c.c=bb.b
where a=1;
A B C
---------- ---------- ----------
1
Another bug with lateral
Compare the results of the following query with the clause “fetch first 2 rows only”
with
t1(a) as (select * from table(odcinumberlist(1,3)))
,t2(a,b) as (select * from table(ku$_objnumpairlist(
sys.ku$_objnumpair(1,1),
sys.ku$_objnumpair(1,2),
sys.ku$_objnumpair(1,3),
sys.ku$_objnumpair(3,1),
sys.ku$_objnumpair(3,2),
sys.ku$_objnumpair(3,3)
)))
,t(id) as (select * from table(odcinumberlist(1,2,3,4,5,6,7)))
select
*
from t,
lateral(select t1.a,t2.b
from t1,t2
where t1.a = t2.a
and t1.a = t.id
order by t2.b
fetch first 2 rows only
)(+)
order by id;
ID A B
---------- ---------- ----------
1 1 1
1 3 1
2 1 1
2 3 1
3 1 1
3 3 1
4 1 1
4 3 1
5 1 1
5 3 1
6 1 1
6 3 1
7 1 1
7 3 1
14 rows selected.
with this one (i’ve just commented out the line with “fetch-first-rows-only”:
with
t1(a) as (select * from table(odcinumberlist(1,3)))
,t2(a,b) as (select * from table(ku$_objnumpairlist(
sys.ku$_objnumpair(1,1),
sys.ku$_objnumpair(1,2),
sys.ku$_objnumpair(1,3),
sys.ku$_objnumpair(3,1),
sys.ku$_objnumpair(3,2),
sys.ku$_objnumpair(3,3)
)))
,t(id) as (select * from table(odcinumberlist(1,2,3,4,5,6,7)))
select
*
from t,
lateral(select t1.a,t2.b
from t1,t2
where t1.a = t2.a
and t1.a = t.id
order by t2.b
-- fetch first 2 rows only
)(+)
order by id;
ID A B
---------- ---------- ----------
1 1 2
1 1 3
1 1 1
2
3 3 2
3 3 1
3 3 3
4
5
6
7
11 rows selected.
Obviously, the first query should return less rows than second one, but we can see that it returned more rows and join predicate “and t1.a = t.id” was ignored, because A and B are not empty and “A” is not equal to t.ID.
Lateral view decorrelation(VW_DCL) causes wrong results with rownum
Everyone knows that rownum in inline views blocks many query transformations, for example pushing/pulling predicates, scalar subquery unnesting, etc, and many people use it for such purposes as a workaround to avoid unwanted transformations(or even CBO bugs).
Obviously, the main reason of that is different calculation of rownum:
If we pull the predicate “column_value = 3″ from the following query to higher level
[sourcecode language=”sql” highlight=””]
select *
from (select * from table(odcinumberlist(1,1,1,2,2,2,3,3,3)) order by 1)
where rownum <= 2
and column_value = 3;
COLUMN_VALUE
————
3
3
[/sourcecode]
we will get different results:
[sourcecode language=”sql” highlight=”8″]
select *
from (select *
from (select * from table(odcinumberlist(1,1,1,2,2,2,3,3,3)) order by 1)
where rownum <= 2
)
where column_value = 3;
no rows selected
[/sourcecode]
Doc ID 62340.1
[collapse]
But we recently encountered a bug with it: lateral view with ROWNUM returns wrong results in case of lateral view decorrelation.
Compare results of this query with and without no_decorrelation hint:
with
t1(a) as (select * from table(odcinumberlist(1,3)))
,t2(b) as (select * from table(odcinumberlist(1,1,3,3)))
,t(id) as (select * from table(odcinumberlist(1,2,3)))
select
*
from t,
lateral(select/*+ no_decorrelate */ rownum rn
from t1,t2
where t1.a=t2.b and t1.a = t.id
)(+)
order by 1,2;
ID RN
---------- ----------
1 1
1 2
2
3 1
3 2
|
with
t1(a) as (select * from table(odcinumberlist(1,3)))
,t2(b) as (select * from table(odcinumberlist(1,1,3,3)))
,t(id) as (select * from table(odcinumberlist(1,2,3)))
select
*
from t,
lateral(select rownum rn
from t1,t2
where t1.a=t2.b and t1.a = t.id
)(+)
order by 1,2;
ID RN
---------- ----------
1 1
1 2
2
3 3
3 4
|
Of course, we can draw conclusions even from these results: we can see that in case of decorrelation(query with hint) rownum was calculated before the join. But to be sure we can check optimizer’s trace 10053:
Final query after transformations:
[sourcecode language=”sql”]
******* UNPARSED QUERY IS *******
SELECT VALUE(KOKBF$2) "ID", "VW_DCL_76980902"."RN" "RN"
FROM TABLE("ODCINUMBERLIST"(1, 2, 3)) "KOKBF$2",
(SELECT ROWNUM "RN_0", VALUE(KOKBF$0) "ITEM_3"
FROM TABLE("ODCINUMBERLIST"(1, 3)) "KOKBF$0",
TABLE("ODCINUMBERLIST"(1, 1, 3, 3)) "KOKBF$1"
WHERE VALUE(KOKBF$0) = VALUE(KOKBF$1)
) "VW_DCL_76980902"
WHERE "VW_DCL_76980902"."ITEM_3"(+) = VALUE(KOKBF$2)
ORDER BY VALUE(KOKBF$2), "VW_DCL_76980902"."RN"
*************************
[/sourcecode]
[collapse]
I’ll modify it a bit just to make it more readable:
we can see that
select
*
from t,
lateral(select rownum rn
from t1,t2
where t1.a=t2.b and t1.a = t.id)(+)
order by 1,2;
was transformed to
select
t.id, dcl.rn
from t,
(select rownum rn
from t1,t2
where t1.a=t2.b) dcl
where dcl.a(+) = t.id
order by 1,2;
And it confirms that rownum was calculated on the different dataset (t1-t2 join) without join filter by table t.
I created SR with Severity 1 (SR #3-19117219271) more than a month ago, but unfortunately Oracle development doesn’t want to fix this bug and moreover they say that is not a bug. So I think this is a dangerous precedent and probably soon we will not be able to be sure in the calculation of rownum and old fixes…
Oracle issues after upgrade to 12.2
Sometimes it’s really hard even to create reproducible test case to send it to oracle support, especially in case of intermittent errors.
In such cases, I think it would be really great to have access to similar service requests or bugs of other oracle clients.
So while my poll about knowledge sharing is still active, I want to share a couple of bugs we have faced after upgrade to 12.2 (and one bug from Eric van Roon). I’m going to remove the bugs from this list when they become “public” or “fixed”.
If you want to add own findings into this list, you can add them into comments. To make this process easier, you can provide just symptomps, short description and the link to own post with details – I’ll add it just as a link.
Continue reading
INDEX FULL SCAN (MIN/MAX) with two identical MIN()
I’ve just noticed an interesting thing:
Assume, that we have a simple query with “MIN(ID)” that works through “Index full scan(MIN/MAX)”:
SQL> explain plan for
2 select
3 min(ID) as x
4 from tab1
5 where ID is not null;
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------
Plan hash value: 4170136576
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 3 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
| 2 | FIRST ROW | | 1 | 4 | 3 (0)| 00:00:01 |
|* 3 | INDEX FULL SCAN (MIN/MAX)| IX_TAB1 | 1 | 4 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("ID" IS NOT NULL)
Test tables
[sourcecode language=”sql”]
create table tab1(id, x, padding)
as
with gen as (select level n from dual connect by level<=1000)
select g1.n, g2.n, rpad(rownum,10,’x’)
from gen g1,gen g2;
create index ix_tab1 on tab1(id, x);
exec dbms_stats.gather_table_stats(”,’TAB1′);
[/sourcecode]
[collapse]
But look what will happen if we add one more “MIN(ID)”:
SQL> explain plan for
2 select
3 min(ID) as x
4 , min(ID)+1000 as x1000
5 from tab1
6 where ID is not null;
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------
Plan hash value: 3397888171
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 3075 (17)| 00:00:02 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
|* 2 | INDEX FAST FULL SCAN| IX_TAB1 | 999K| 3906K| 3075 (17)| 00:00:02 |
---------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("ID" IS NOT NULL)
Bug with xmltable, xmlnamespaces and xquery_string specified using bind variable
Today I was asked about strange problem: xmltable does not return data, if xquery specified by bind variable and xml data has xmlnamespaces:
SQL> var x_path varchar2(100); SQL> var x_xml varchar2(4000); SQL> col x format a100; SQL> begin 2 :x_path:='/table/tr/td'; 3 :x_xml :=q'[ 4 <table xmlns="http://www.w3.org/tr/html4/"> 5 <tr> 6 <td>apples</td> 7 <td>bananas</td> 8 </tr> 9 </table> 10 ]'; 11 end; 12 / PL/SQL procedure successfully completed. SQL> select 2 i, x 3 from xmltable( xmlnamespaces(default 'http://www.w3.org/tr/html4/'), 4 :x_path -- bind variable 5 --'/table/tr/td' -- same value as in the variable "X_PATH" 6 passing xmltype(:x_xml) 7 columns i for ordinality, 8 x xmltype path '.' 9 ); no rows selected
But if we comment bind variable and comment out literal x_query ‘/table/tr/td’, query will return data:
SQL> select
2 i, x
3 from xmltable( xmlnamespaces(default 'http://www.w3.org/tr/html4/'),
4 --:x_path -- bind variable
5 '/table/tr/td' -- same value as in the variable "X_PATH"
6 passing xmltype(:x_xml)
7 columns i for ordinality,
8 x xmltype path '.'
9 );
I X
---------- -------------------------------------------------------------------
1 <td xmlns="http://www.w3.org/tr/html4/">apples</td>
2 <td xmlns="http://www.w3.org/tr/html4/">bananas</td>
2 rows selected.
The only workaround I found is the specifying any namespace in the x_query – ‘/*:table/*:tr/*:td’
SQL> exec :x_path:='/*:table/*:tr/*:td'
PL/SQL procedure successfully completed.
SQL> select
2 i, x
3 from xmltable( xmlnamespaces(default 'http://www.w3.org/tr/html4/'),
4 :x_path -- bind variable
5 passing xmltype(:x_xml)
6 columns i for ordinality,
7 x xmltype path '.'
8 );
I X
---------- -------------------------------------------------------------------
1 <td xmlns="http://www.w3.org/tr/html4/">apples</td>
2 <td xmlns="http://www.w3.org/tr/html4/">bananas</td>
2 rows selected.
It’s quite ugly solution, but I’m not sure whether there is another solution…
REGEXP_LIKE: strange unspecified value in parameter “modifier”
Today I noticed strange thing in predicate section of execution plan for simple query with regexp_like, where 3rd parameter “MODIFIER” was not specified:
SQL> select * from dual where regexp_like(dummy,'.');
D
-
X
SQL> select * from table(dbms_xplan.display_cursor);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------
SQL_ID 97xuqf9cmjsta, child number 0
-------------------------------------
select * from dual where regexp_like(dummy,'.')
Plan hash value: 272002086
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 2 (100)| |
|* 1 | TABLE ACCESS FULL| DUAL | 1 | 2 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter( REGEXP_LIKE ("DUMMY",'.',HEXTORAW('F07FD85CFF0700006A1116
45010000000000000000000000FC12164501000000000000000000000000000000000000
0010000000000000001880D85CFF07000002000000000000000000000081000000') ))
20 rows selected.
It is particularly interesting that the values in HEXTORAW() are always different for different first parameters:
SQL> select * from dual where regexp_like(dummy,'x');
...
1 - filter( REGEXP_LIKE ("DUMMY",'x',HEXTORAW('3895D330FF0700006A1116
45010000000000000000000000FC12164501000000000000000000000000000000000000
0011000000000000006895D330FF07000002000000000000000000000081000000') ))
SQL> select * from dual where regexp_like(dummy,'y');
...
1 - filter( REGEXP_LIKE ("DUMMY",'y',HEXTORAW('00DA3C3FFF0700006A1116
45010000000000000000000000FC12164501000000000000000000000000000000000000
00110000000000000030DA3C3FFF07000002000000000000000000000081000000') ))
SQL> select * from dual where regexp_like(dummy||'','x')
...
1 - filter( REGEXP_LIKE ("DUMMY"||'','x',HEXTORAW('70964F2FFF0700006A
111645010000000000000000000000FC1216450100000000000000000000000000000000
0000001100000000000000A0964F2FFF07000002000000000000000000000081000000')
))
I don’t know, what does it mean, but it looks like garbage from memory.
When I noticed this, I decided to check how regexp_like will work in function-based indexes:
SQL> create table xtest as
2 select dummy||level as str
3 from dual
4 connect by level<=30;
Table created.
SQL> select * from xtest where case when regexp_like(str,'1') then 1 end = 1;
...
12 rows selected.
SQL> select * from table(dbms_xplan.display_cursor);
PLAN_TABLE_OUTPUT
-----------------------------------------------------------------------------------------
SQL_ID 7ztp0k8c1zn2h, child number 0
-------------------------------------
select * from xtest where case when regexp_like(str,'1') then 1 end = 1
Plan hash value: 4207139086
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 3 (100)| |
|* 1 | TABLE ACCESS FULL| XTEST | 12 | 264 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(CASE WHEN REGEXP_LIKE
("STR",'1',HEXTORAW('68F9CB32FF0700006A111645010000000000000000000000FC1
216450100000000000000000000000000000000000000110000000000000098F9CB32FF0
7000002000000000000000000000081000000') ) THEN 1 END =1)
SQL> create index xtest_fbi on xtest(case when regexp_like(str,'1') then 1 end);
Index created.
SQL> select * from xtest where case when regexp_like(str,'1') then 1 end = 1;
...
12 rows selected.
SQL> select * from table(dbms_xplan.display_cursor);
PLAN_TABLE_OUTPUT
-----------------------------------------------------------------------------------------
SQL_ID 7ztp0k8c1zn2h, child number 0
-------------------------------------
select * from xtest where case when regexp_like(str,'1') then 1 end = 1
Plan hash value: 1479471124
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 2 (100)| |
| 1 | TABLE ACCESS BY INDEX ROWID| XTEST | 12 | 300 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | XTEST_FBI | 12 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("XTEST"."SYS_NC00002$"=1)
SQL> select column_expression from user_ind_expressions e where e.index_name='XTEST_FBI';
COLUMN_EXPRESSION
-----------------------------------------------------------------------------------------
CASE WHEN REGEXP_LIKE ("STR",'1') THEN 1 END
As you can see it works fine, although the predicate from first execution plan differs from the FBI expression.
Then I dumped 10053 trace and noticed that the HEXTORAW(…) function appeared in “Explain Plan Dump” only, so it looks just like plan output bug.
Patch for “Bug 16516751 : Suboptimal execution plan for query with join and in-list using composite index” is available now
Bug about which i wrote previously is fixed now in 12.2, and patch 16516751 is available now for 11.2.0.3 Solaris64.
Changes:
1. CBO can consider filters in such cases now
2. Hint NUM_INDEX_KEYS fixed and works fine
UPD: Very interesting solution by Igor Usoltsev(in russian):
Ignored hint USE_CONCAT(OR_PREDICATES(N)) allows to avoid inlist iterator.
Example:
select--+ USE_CONCAT(OR_PREDICATES(32767))
* from xt1,xt2
where
xt1.b=10
and xt1.a=xt2.a
and xt2.b in (1,2)
/
Plan hash value: 2884586137 -- good plan:
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 401 (100)| |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 100 | 36900 | 401 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| XT1 | 100 | 31000 | 101 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | IX_XT1 | 100 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | IX_XT2 | 1 | | 2 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID | XT2 | 1 | 59 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("XT1"."B"=10)
5 - access("XT1"."A"="XT2"."A")
filter(("XT2"."B"=1 OR "XT2"."B"=2))
From 10053 trace on nonpatched 11.2.0.3:
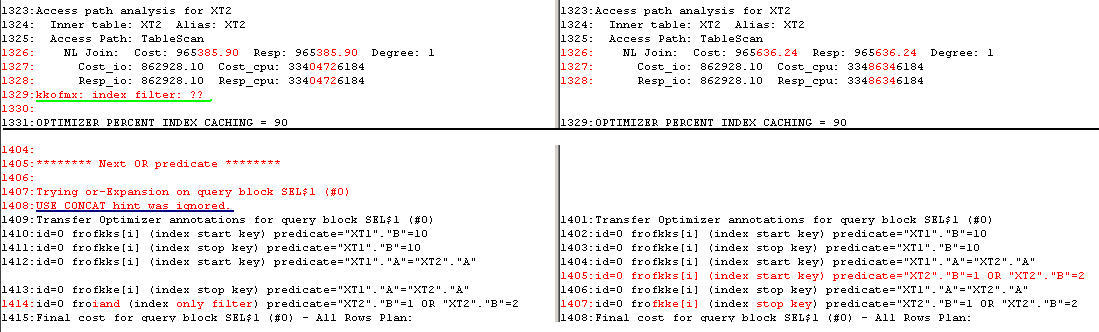
Workaround for deadlock with select for update order by on 11.2.0.2-11.2.0.3
There is well-known bug with “for update order by” on 11.2, when rows locks not in specified order, although the ordering occurs.
I already wrote on my russian blog about the appearance of “buffer sort” in plans with “for update” even if sort order was not specified. And this behavior can be disabled for example by specifying /*+ opt_param( ‘optimizer_features_enable’ ‘11.1.0.7’ ) */.
But if we want to solve problem with deadlock, we need to force index full scan/index range scan ascending with “buffer sort” usage.
UPD: The patch is already available for 11.2.0.2 and 11.2.0.3: Patch 13371104: LOCK ORDER HAS CHANGED BETWEEN 10.2.0.5 AND 11.2.0.2.
Read more: Simple example