It seems strange to me:
When all needed columns are in the index, filter predicates are expectedly applied to the index
select a,b from xt_test where a=1 and
(:b is null or b = :b)
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 2 |
|* 1 | INDEX RANGE SCAN| PK_XT_TEST | 1 | 1 | 1 |00:00:00.01 | 2 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("A"=1)
filter((:B IS NULL OR "B"=:B))
But if I add another column “PAD”, the filter moves to the table filters:
select a,b,pad from xt_test where a=1
and (:b is null or b = :b)
---------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | Buffers |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 | 4 |
|* 1 | TABLE ACCESS BY INDEX ROWID| XT_TEST | 1 | 1 | 1 | 4 |
|* 2 | INDEX RANGE SCAN | PK_XT_TEST | 1 | 10 | 10 | 2 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter((:B IS NULL OR "B"=:B))
2 - access("A"=1)
As workaround we can use something like that:
select--+ NO_ELIMINATE_JOIN(t) NO_ELIMINATE_JOIN(t2@sel$2) gather_plan_statistics
a,b,pad
from xt_test t
where t.rowid in ( select t2.rowid
from xt_test t2
where a=1
and (:b is null or b = :b)
);
Plan hash value: 1464320522
--------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows |Buffers |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 | 3 |
| 1 | NESTED LOOPS | | 1 | 1 | 1 | 3 |
|* 2 | INDEX RANGE SCAN | PK_XT_TEST | 1 | 1 | 1 | 2 |
| 3 | TABLE ACCESS BY USER ROWID| XT_TEST | 1 | 1 | 1 | 1 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("A"=1)
filter((:B IS NULL OR "B"=:B))
[sourcecode language=”sql”]
create table xt_test(a,b,pad,constraint pk_xt_test primary key(a,b))
as select
mod(rownum,10) a
,rownum b
,rpad(rownum,10) pad
from dual
connect by level<=100;
call dbms_stats.gather_table_stats(”,’XT_TEST’);
var b number;
exec :b:=1;
select/*+ gather_plan_statistics */
a,b,pad
from xt_test
where a=1 and (:b is null or b = :b);
select * from table(dbms_xplan.display_cursor(”,”,’allstats last’));
select/*+ gather_plan_statistics */
a,b
from xt_test
where a=1 and (:b is null or b = :b);
select * from table(dbms_xplan.display_cursor(”,”,’allstats last’));
select–+ NO_ELIMINATE_JOIN(t) NO_ELIMINATE_JOIN(t2@sel$2) gather_plan_statistics
a,b,pad
from xt_test t
where t.rowid in ( select t2.rowid
from xt_test t2
where a=1
and (:b is null or b = :b)
);
select * from table(dbms_xplan.display_cursor(”,”,’allstats last’));
[/sourcecode]
Update:
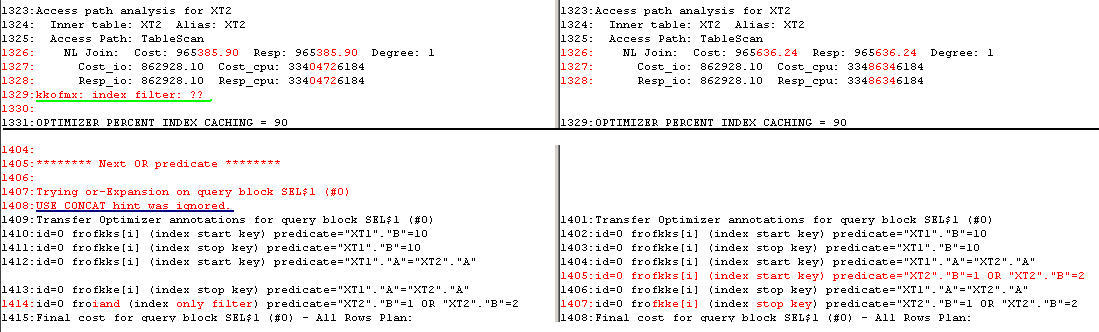
I just forgot to mention that there is another workaround – to force concatenation:
SQL> select--+ use_concat(or_predicates(2))
2 a,b,pad
3 from xt_test where a=1 and (:b is null or b = :b);
A B PAD
---------- ---------- ----------------------------------------
1 1 1
Plan hash value: 3582916188
----------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers | Reads |
----------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 3 (100)| 1 |00:00:00.01 | 2 | 2 |
| 1 | CONCATENATION | | 1 | | | 1 |00:00:00.01 | 2 | 2 |
| 2 | TABLE ACCESS BY INDEX ROWID | XT_TEST | 1 | 1 | 1 (0)| 1 |00:00:00.01 | 2 | 2 |
|* 3 | INDEX UNIQUE SCAN | PK_XT_TEST | 1 | 1 | 0 (0)| 1 |00:00:00.01 | 1 | 1 |
|* 4 | FILTER | | 1 | | | 0 |00:00:00.01 | 0 | 0 |
| 5 | TABLE ACCESS BY INDEX ROWID| XT_TEST | 0 | 10 | 2 (0)| 0 |00:00:00.01 | 0 | 0 |
|* 6 | INDEX RANGE SCAN | PK_XT_TEST | 0 | 10 | 1 (0)| 0 |00:00:00.01 | 0 | 0 |
----------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("A"=1 AND "B"=:B)
4 - filter(:B IS NULL)
6 - access("A"=1)
filter(LNNVL("B"=:B))