
I created this simple service a couple of years ago. It’s pretty simple, small and intuitive Python app, so you can easily modify it to suit your own needs and run on any platform: https://github.com/xtender/pySync
Category Archives: oracle
Format SQL or PL/SQL directly in Oracle database
Obviously we can format/beautify SQL or PL/SQL code using external tools, but sometimes it would be more convenient to format it directly in database, for example if we want to see few different sql_text’s from v$sqlarea. And thanks to Oracle SqlCL and Oracle SQL Developer, we can easily use oracle.dbtools.app.Format function from their Java library dbtools-common.jar, so if you use SqlCL or SQL Developer, you can use the same formatting options.
1. load appropriate java library into Oracle
You may have already installed SQLDeveloper or SqlCL on your database server, just check $ORACLE_HOME/sqldeveloper or $ORACLE_HOME/sqcl directories. If – not, you need to download appropriate SqlCL version that matches your java version in Oracle. For 12.2 – 19.8 you can download latest SqlCL 20.3. In fact we need just dbtools-common.jar from lib directory. I put it into $ORACLE_HOME/sqlcl/lib directory on the server and load it using loadjava:
Continue readingFunny friday Oracle SQL quiz: query running N seconds
Write a pure SQL query with PL/SQL that stop after :N seconds, where :N is a bind variable.
My solution
[sourcecode language=”sql”]
with v(start_hsecs, delta, flag) as (
select
hsecs as start_hsecs, 0 as delta, 1 as flag
from v$timer
union all
select
v.start_hsecs,
(t.hsecs-v.start_hsecs)/100 as delta,
case when (t.hsecs-v.start_hsecs)/100 > :N /* seconds */ then v.flag*-1 else v.flag+1 end as flag
from v, v$timer t
where v.flag>0 and t.hsecs>=v.start_hsecs
)
select delta
from v
where 0>flag
/
–end
[/sourcecode]
[collapse]
SQL> var N number
SQL> exec :N := 3 /* seconds */;
PL/SQL procedure successfully completed.
SQL> select...
DELTA
----------
3.01
1 row selected.
Elapsed: 00:00:03.01
Another my solution using sys.standard.current_timestamp, so some internal pl/sql…:
select count(*) from dual
connect by sys.standard.current_timestamp - current_timestamp <= interval'3'second;
Serial Scans failing to offload
Very Large Buffer Cache
We’ve observed databases with very large buffer caches where Serial Scans don’t make use of Smart Scan when that would have executed faster: improvements to the decision making for Serial Scans have been made under bug 31626438. This fix is back-portable.
A key difference between PQ and Serial is that as part of granule generation PQ sums the sizes of all the partitions that have not been pruned and passes that total size to the buffer cache decision making logic. Because the entire size to be scanned is considered, we make an accurate determination of smart scan benefits and the risk of cache thrashing.
Serial Scans on partitioned tables do not involved the coordinator and have no opportunity to get the larger picture, instead they start work immediately so each partition is considered one at a time and only that one partition’s size is considered by the decision for using Buffer Cache or Direct Read (and hence offload). In the presence of very large buffer caches any given partition can fail the “Is Medium” test (or even the “Is Small” test) and so not get offloaded.
In order to avoid this situation an upper bound of 100MB for using a buffer cache scan has been implemented for any serially scanned segment that:
- isn’t using Automatic Big Table Caching (ABTC).
- hasn’t had the Small Table parameter changed to a non-default value.
Any partitions larger than 100 MB will now automatically use Direct Read and hence offload on Exadata.
See also: Part 1
See also: Part 2
NSMTIO: kxfxghwm:[HWM_NOT_FOUND]
Another case to watch out for is when NSMTIO tracing shows HWM_NOT_FOUND and then choosing a Buffer Cache scan when a Direct Read offloaded scan would have been faster. This can happen when a PQ query gets executed serially (NB: this is NOT the downgrade to serial case, this is still PQ but on a single thread). In this case the coordinator again does not have the opportunity to process all the partitions and as part of that gather the High Water Mark (HWM) for each segment and checkpoint them so we fall back on buffer cache scans. A fix for this is currently being investigated.
Mixed Block Sizes
I have consistently advised against mixing block sizes in a database without a compelling reason backed up by empirical evidence, but for those who must the “Is Medium Table” logic for whether to use buffer cache or direct read has been improved when the database has more than one block size in use. This is tracked by bug 24655250 and fixed in 20.1.
See also Random thoughts on block sizes
Simple function returning Parallel slave info
You can add also any information from v$rtsm_sql_plan_monitor if needed
create or replace function px_session_info return varchar2 parallel_enable as
vSID int;
res varchar2(30);
begin
vSID:=userenv('sid');
select
to_char(s.server_group,'fm000')
||'-'||to_char(s.server_set,'fm0000')
||'-'||to_char(s.server#,'fm0000')
||'('||s.sid||','||s.degree||'/'||s.req_degree||')'
into res
from v$px_session s
where s.sid=vSID;
return res;
exception when no_data_found then
return 'no_parallel';
end;
/
Simple example:
select--+ parallel
px_session_info, count(*)
from sys.obj$
group by px_session_info
/
PX_SESSION_INFO COUNT(*)
------------------------ --------
001-0002-0001(630,2/2) 38298
001-0002-0002(743,2/2) 34706
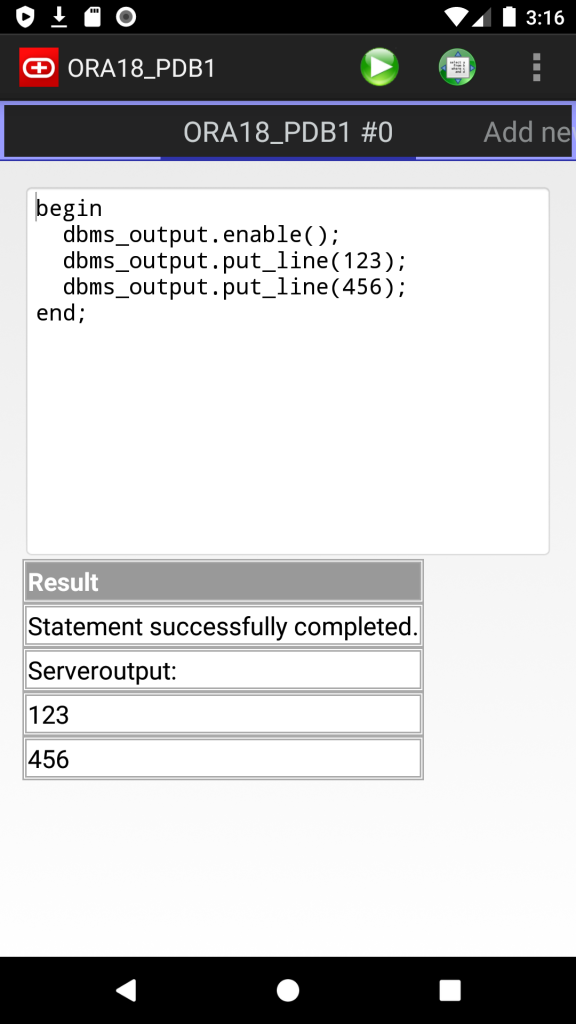
Android Oracle Client 2.0
I’ve just released new version of my Simple Android Oracle Client.
New features:
- Supported Oracle versions: 11.2, 12.1, 12.2, 18, 19, 20.
- SQL Templates: now you can save and load own script templates
- Server output (dbms_output)
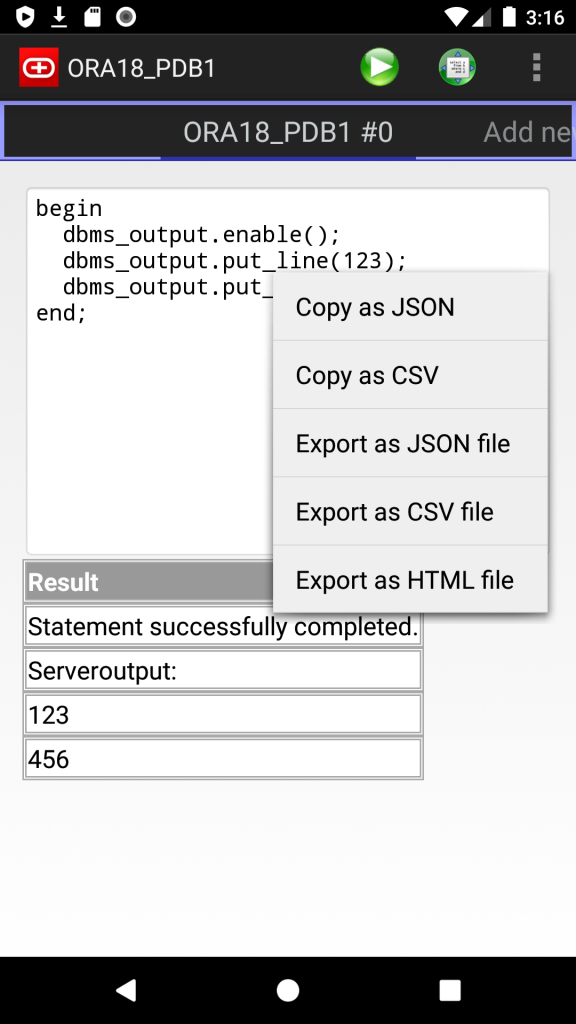
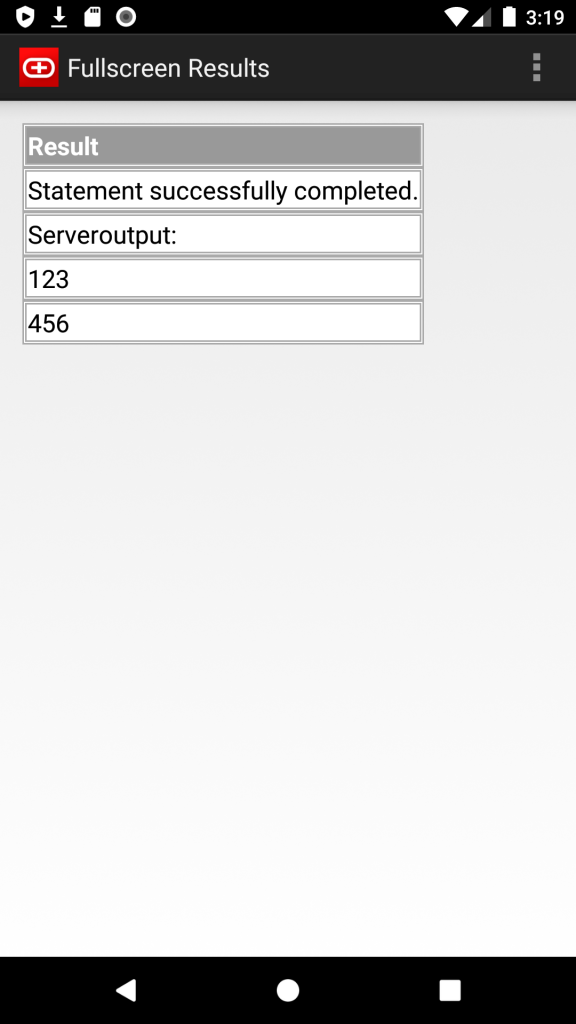
- Export results as JSON, CSV and HTML files (long tap on results)
- Copy results to the Clipboard as JSON or CSV
I use it just for basic troubleshooting and small fixes, but, please, let me know if you need anything else.
Screenshots:
Smart Scan and Recursive queries
Since Christmas I have been asked to investigate two different “failures to use Smart Scan”. It turns out they both fell into the same little known restriction on the use of Direct Read. Smart Scan critically depends on Direct Read in order to read the synthetic output blocks into private buffers in PGA so with Direct Read disabled Smart Scan is also disabled. In these two cases the restriction is on using Direct Read on Serial Recursive queries.
Case 1: Materialized View Refresh
A customer asked me to investigate why his MView refresh was running slowly and was failing to use Smart Scan. He had used 'trace[NSMTIO] disk=highest' which showed the cause as:
Direct Read for serial qry: disabled(::recursive_call::kctfsage:::)
PL/SQL functions and statement level consistency
You may know that whenever you call PL/SQL functions from within SQL query, each query in the function is consistent to the SCN of its start and not to the SCN of parent query.
Simple example:
create table test as
select level a, level b from dual connect by level<=10;
create or replace function f1(a int) return int as
res int;
begin
select b into res
from test t
where t.a=f1.a;
dbms_lock.sleep(1);
return res;
end;
/
As you can see we created a simple PL/SQL function that returns the result of the query select b from test where a=:input_var
But lets check what does it return if another session changes data in the table:
-- session 2:
begin
for i in 1..30 loop
update test set b=b+1;
commit;
dbms_lock.sleep(1);
end loop;
end;
/
-- session 1:
SQL> select t.*, f1(a) func from test t;
A B FUNC
---------- ---------- ----------
1 1 1
2 2 3
3 3 5
4 4 7
5 5 9
6 6 11
7 7 13
8 8 15
9 9 17
10 10 19
10 rows selected.
As you can see we got inconsistent results in the column FUNC, but we can easily fix it using OPERATORs:
CREATE OPERATOR f1_op
BINDING (INT)
RETURN INT
USING F1;
Lets revert changes back and check our query with new operator now:
--session 1:
SQL> update test set b=a;
10 rows updated.
SQL> commit;
Commit complete.
-- session 2:
begin
for i in 1..30 loop
update test set b=b+1;
commit;
dbms_lock.sleep(1);
end loop;
end;
/
-- session 1:
SQL> select t.*, f1(a) func, f1_op(a) op from test t;
A B FUNC OP
---------- ---------- ---------- ----------
1 2 2 2
2 3 5 3
3 4 8 4
4 5 11 5
5 6 14 6
6 7 17 7
7 8 20 8
8 9 23 9
9 10 26 10
10 11 29 11
10 rows selected.
As you can see, all values in the column OP are equal to the values of B, while, in turn, function F1 returns inconsistent values.
Just short note for myself: OJPPD limitations
As of Oracle 19c OJPPD doesn’t support connect-by and TABLE():
OJPPD: OJPPD bypassed: query block contains START WITH/CONNECT BY.
OJPPD: OJPPD bypassed: View contains TABLE expression.
My presentations from RuOUG meetups
I forgot to share my files from presentations, so I’m going to keep them here: