
In one of the previous posts I showed How even empty trigger increases redo generation, but running the test from that post, I have found that this behaviour a bit changed on 12.2:
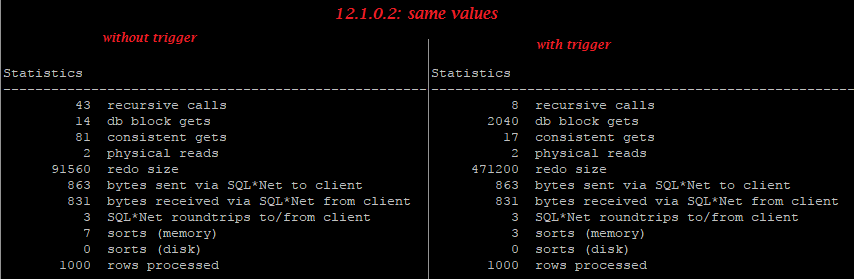
In my old test case, values of column A were equal to values of B, and on previous oracle versions including 12.1.0.2 we can see that even though “update … set B=A” doesn’t change really “B”, even empty trigger greatly increases redo generation.
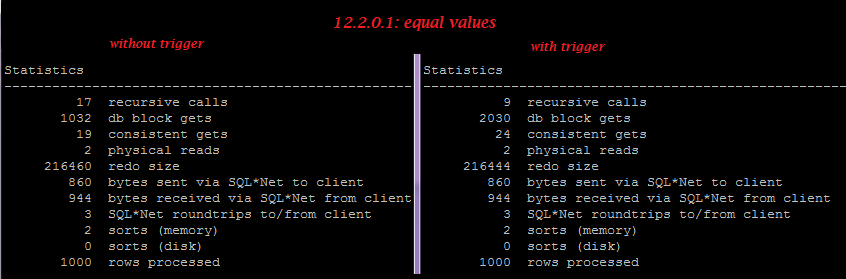
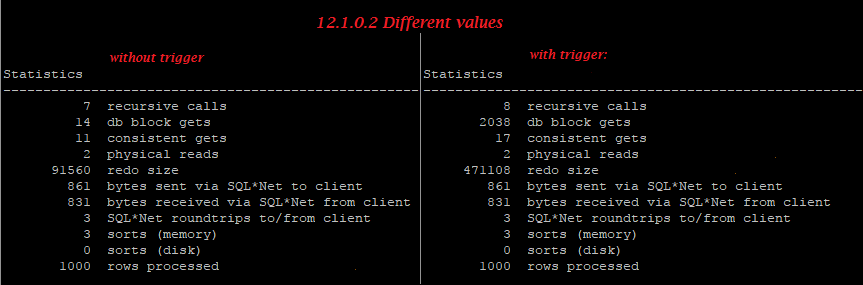
But on 12.2.0.1 in case of equal values, the trigger doesn’t increase redo, so we can see small optimization here, though in case of different values, the trigger still increases reado generation greatly.
[sourcecode language=”sql”]
set feed on;
drop table xt_curr1 purge;
drop table xt_curr2 purge;
— simple table:
create table xt_curr1 as select ‘2’ a, ‘2’ b from dual connect by level<=1000;
— same table but with empty trigger:
create table xt_curr2 as select ‘2’ a, ‘2’ b from dual connect by level<=1000;
create or replace trigger tr_xt_curr2 before update on xt_curr2 for each row
begin
null;
end;
/
— objectID and SCN:
col obj1 new_val obj1;
col obj2 new_val obj2;
col scn new_val scn;
select
(select o.OBJECT_ID from user_objects o where o.object_name=’XT_CURR1′) obj1
,(select o.OBJECT_ID from user_objects o where o.object_name=’XT_CURR2′) obj2
,d.CURRENT_SCN scn
from v$database d
/
— logfile1:
alter system switch logfile;
col member new_val logfile;
SELECT member
FROM v$logfile
WHERE
is_recovery_dest_file=’NO’
and group#=(SELECT group# FROM v$log WHERE status = ‘CURRENT’)
and rownum=1;
— update1:
set autot trace stat;
update xt_curr1 set b=a;
set autot off;
commit;
— dump logfile1:
alter session set tracefile_identifier=’log1_same’;
ALTER SYSTEM DUMP LOGFILE ‘&logfile’ SCN MIN &scn OBJNO &obj1;
— logfile2:
alter system switch logfile;
col member new_val logfile;
SELECT member
FROM v$logfile
WHERE
is_recovery_dest_file=’NO’
and group#=(SELECT group# FROM v$log WHERE status = ‘CURRENT’)
and rownum=1;
— update2:
set autot trace stat;
update xt_curr2 set b=a;
set autot off;
commit;
— dump logfile2:
alter session set tracefile_identifier=’log2_same’;
ALTER SYSTEM DUMP LOGFILE ‘&logfile’ OBJNO &obj2;
alter session set tracefile_identifier=’off’;
disc;
[/sourcecode]
[sourcecode language=”sql”]
set feed on;
drop table xt_curr1 purge;
drop table xt_curr2 purge;
— simple table:
create table xt_curr1 as select ‘1’ a, ‘2’ b from dual connect by level<=1000;
— same table but with empty trigger:
create table xt_curr2 as select ‘1’ a, ‘2’ b from dual connect by level<=1000;
create or replace trigger tr_xt_curr2 before update on xt_curr2 for each row
begin
null;
end;
/
— objectID and SCN:
col obj1 new_val obj1;
col obj2 new_val obj2;
col scn new_val scn;
select
(select o.OBJECT_ID from user_objects o where o.object_name=’XT_CURR1′) obj1
,(select o.OBJECT_ID from user_objects o where o.object_name=’XT_CURR2′) obj2
,d.CURRENT_SCN scn
from v$database d
/
— logfile1:
alter system switch logfile;
col member new_val logfile;
SELECT member
FROM v$logfile
WHERE
is_recovery_dest_file=’NO’
and group#=(SELECT group# FROM v$log WHERE status = ‘CURRENT’)
and rownum=1;
— update1:
set autot trace stat;
update xt_curr1 set b=a;
set autot off;
commit;
— dump logfile1:
alter session set tracefile_identifier=’log1_diff’;
ALTER SYSTEM DUMP LOGFILE ‘&logfile’ SCN MIN &scn OBJNO &obj1;
— logfile2:
alter system switch logfile;
col member new_val logfile;
SELECT member
FROM v$logfile
WHERE
is_recovery_dest_file=’NO’
and group#=(SELECT group# FROM v$log WHERE status = ‘CURRENT’)
and rownum=1;
— update2:
set autot trace stat;
update xt_curr2 set b=a;
set autot off;
commit;
— dump logfile2:
alter session set tracefile_identifier=’log2_diff’;
ALTER SYSTEM DUMP LOGFILE ‘&logfile’ OBJNO &obj2;
alter session set tracefile_identifier=’off’;
disc;
[/sourcecode]
Equal values:
12.1.0.2:
12.2.0.1:
Different values:
12.1.0.2:
12.2.0.1:
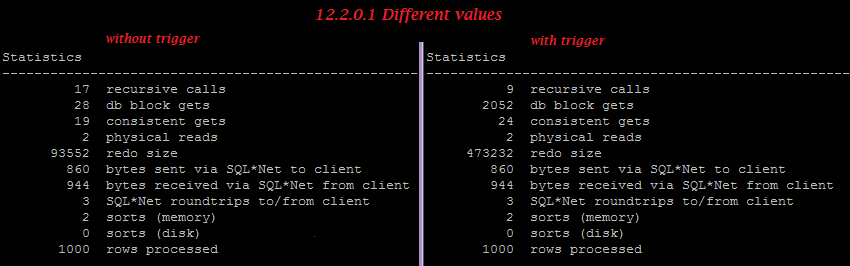
We can easily find that trigger disables batched “Array update”:
