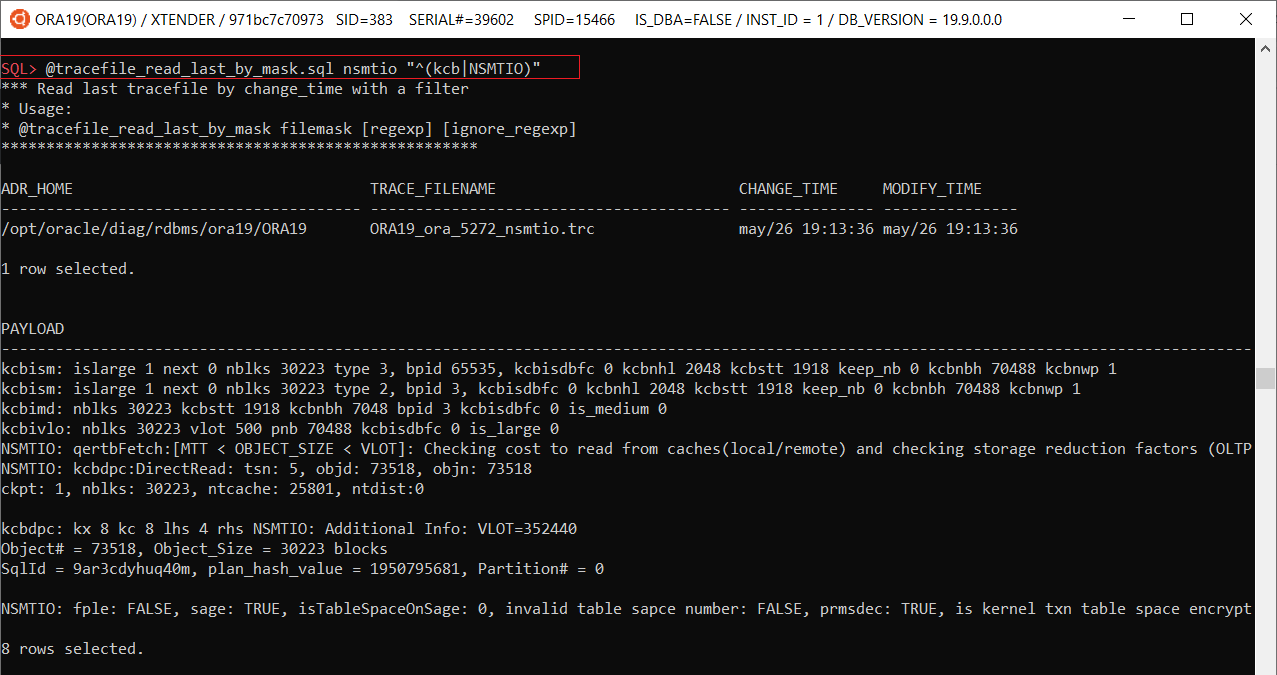
Got an interesting question today in RuOUG:
Some very simple PL/SQL procedures usually are completed within ~50ms, but sometimes sporadically longer than a second. For example, the easiest one from these procedures:
create or replace PROCEDURE XXXX (
P_ORG_NUM IN number,
p_result OUT varchar2,
p_seq OUT number
) AS
BEGIN
p_seq := P_ORG_NUM; p_result:='';
END;
sql_trace shows that it was executed for 1.001sec and all the time was “ON CPU”:
Continue reading