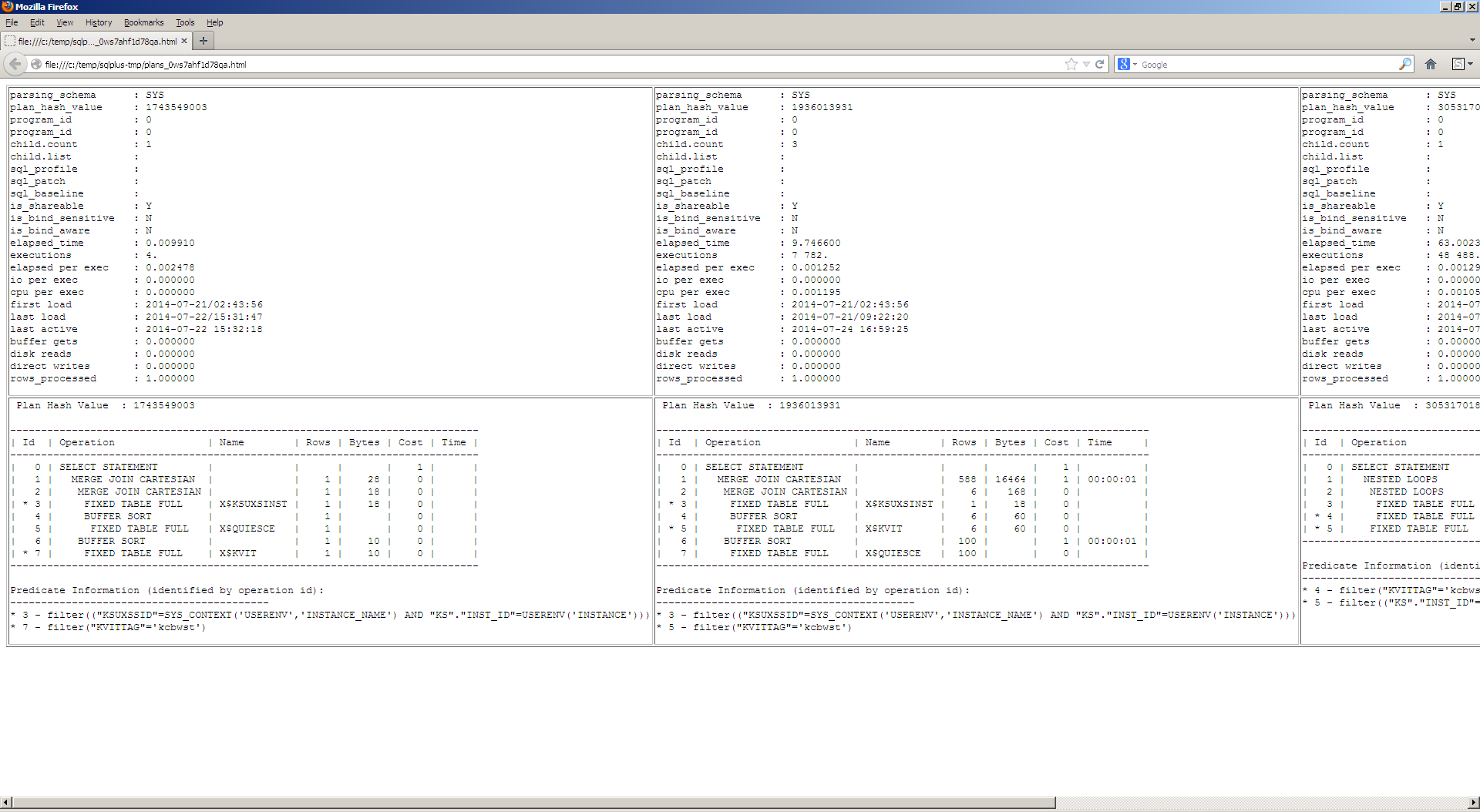
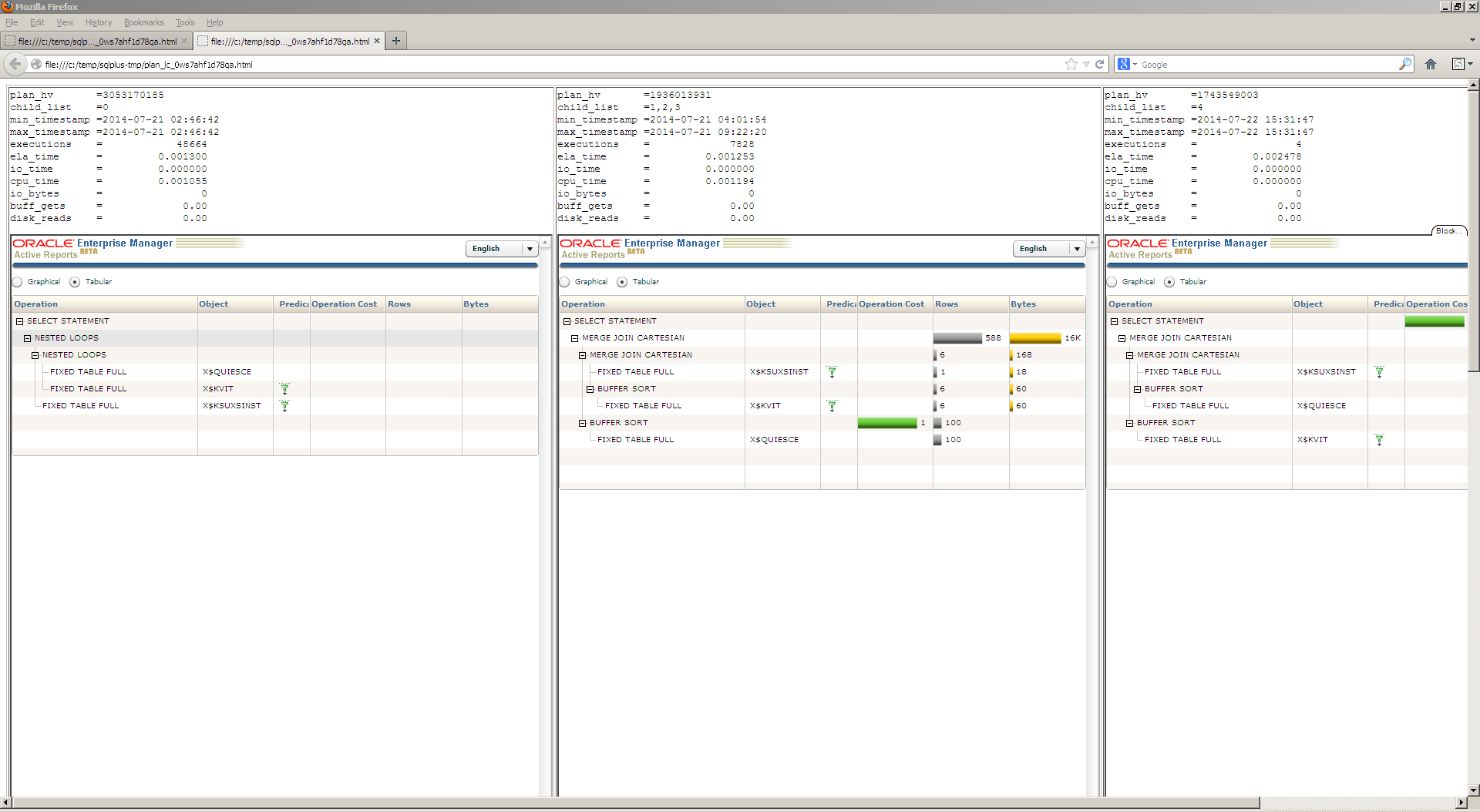
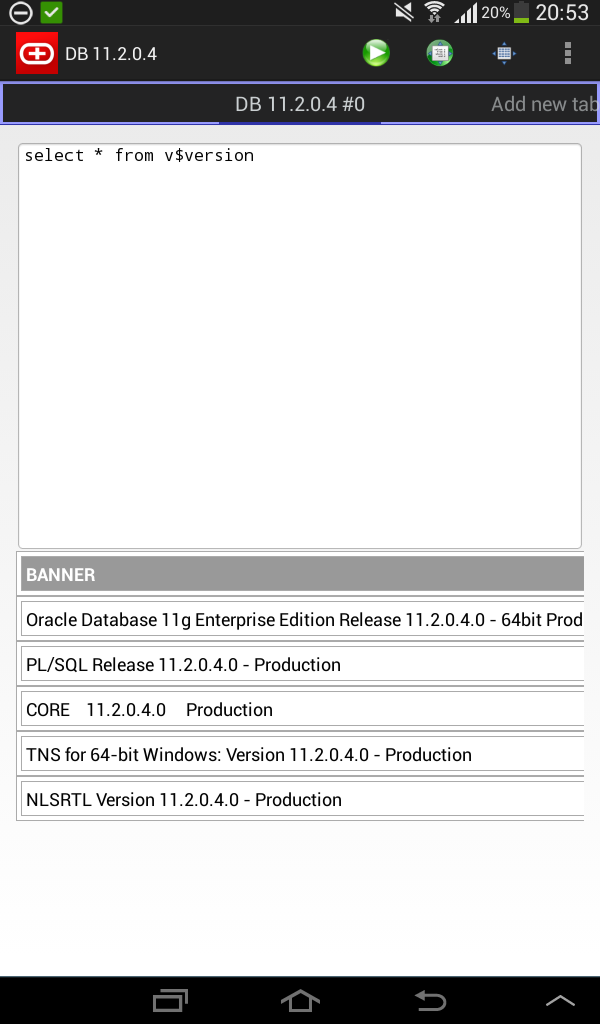
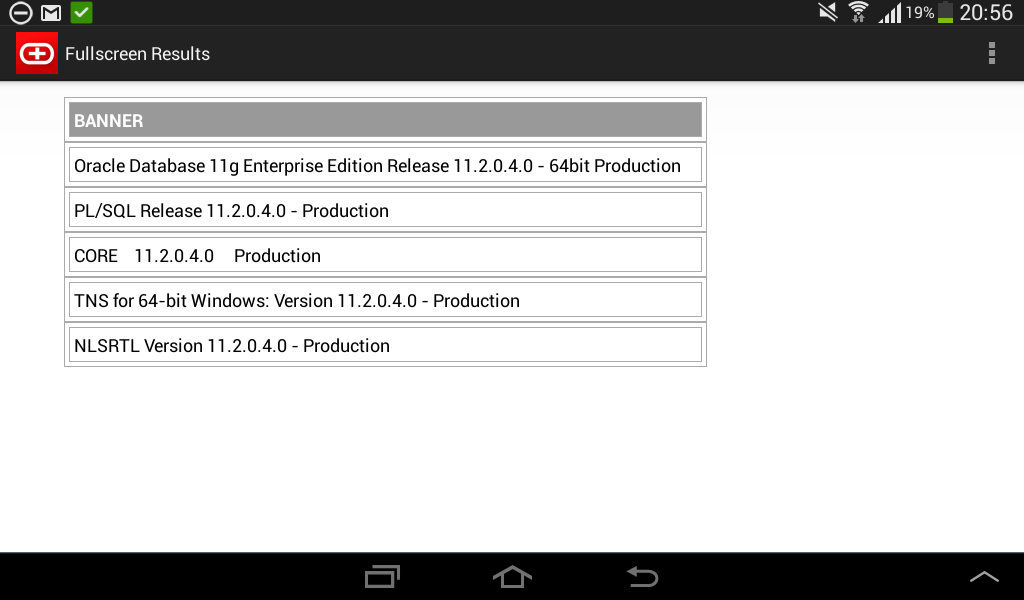
I am happy to announce, that I’ve just published my first android app – ![]() Simple oracle client for android!
Simple oracle client for android!
Since this is only the first version, I’m sure that it contains various UI bugs, so I’ll wait for reviews and bug reports!
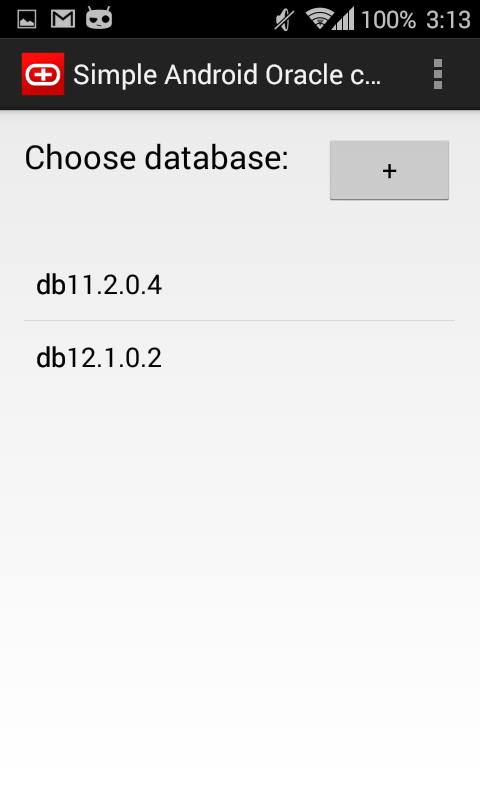
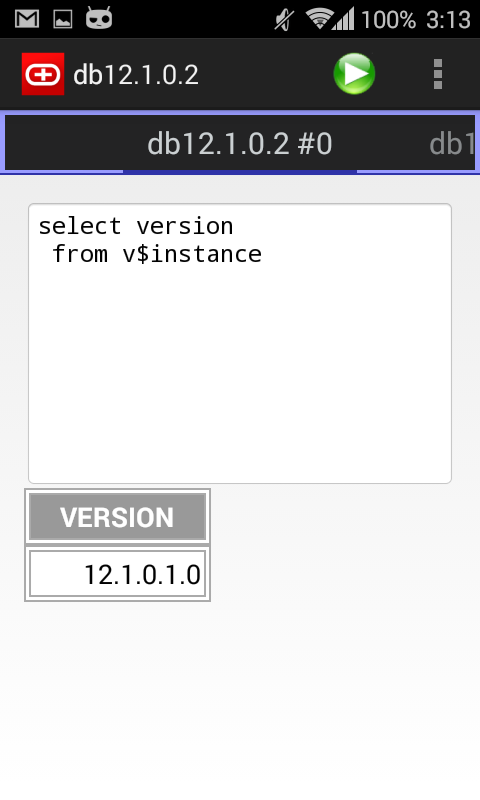
Several screenshots:
 |
 |
 |
 |