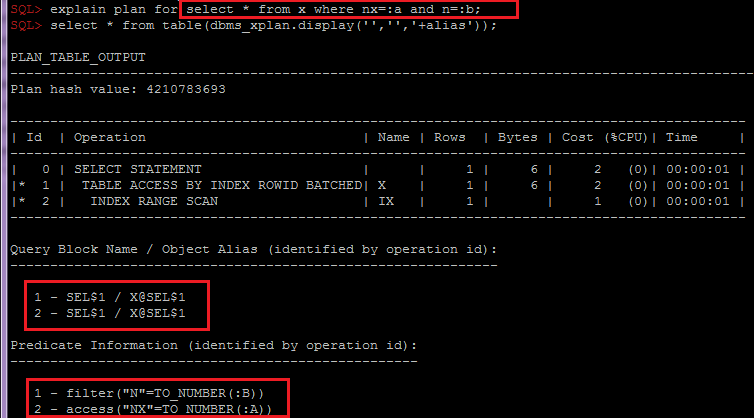
There is a common misconception that partition pruning does not help in the case of global indexes and only works with local indexes or full table scans (FTS).
It is understandable how this misconception arose: indeed, when operations like PARTITION RANGE ITERATOR, PARTITION RANGE SINGLE, etc., appear in execution plans, partition pruning becomes strongly associated with local indexes and FTS.
It is also clear why this is the most noticeable case: the exclusion of partitions in PARTITION RANGE ITERATOR operations is hard to miss, especially since there is a dedicated line for it in the execution plan.
However, this is not all that partition pruning can do. In fact, this way of thinking is not entirely valid, and I will demonstrate this with some simple examples.
Continue reading