
I just noticed that os_command.zip from old oracle white paper was lost, so i decided to post link to my old package, which is like os_command but with timeout parameter: http://github.com/xtender/xt_shell
Oracle 12c: behavior tests of the Inline functions, “Identities” and “defaults”
I have done several minitests:
1. SQL and PL/SQL engines: which functions will be executed if there are two functions with same name as in SQL, as in PL/SQL (like “USER”, LPAD/RPAD, etc..)
– PL/SQL.
PL/SQL
[sourcecode language=”sql”]
SQL> @trace_on
Enter value for trace_identifier: inline
Enter value for level: 12
Tracing was enabled:
TRACEFILE_NAME
—————————————————————————-
/u01/app/oracle/diag/rdbms/xtsql/xtsql/trace/xtsql_ora_21599_inline.trc
SQL> with
2 function inline_user return varchar2 is
3 begin
4 return user;
5 end;
6 select
7 inline_user
8 from dual
9 /
INLINE_USER
——————————
XTENDER
1 row selected.
SQL> @trace_off
— unlike SQL’s "USER", PL/SQL function SYS.STANDARD.USER recursively executes "select user from sys.dual":
SQL> !grep USER /u01/app/oracle/diag/rdbms/xtsql/xtsql/trace/xtsql_ora_21599_inline.trc
SELECT USER FROM SYS.DUAL
SQL>
[/sourcecode]
[collapse]
2. Will there be any context switches if we call the inline functions which contain another pl/sql functions/procedures?
– Yes
Test 1
[sourcecode language=”sql”]
SQL> sho parameter max_string
NAME TYPE VALUE
———————————— ———— ——————————
max_string_size string STANDARD
SQL> @trace_pl_on
Session altered.
SQL> with
2 function blabla(p_str varchar2) return varchar2 is
3 begin
4 return lpad(p_str, 5000, ‘*’);
5 end;
6 select
7 length(blabla(dummy)) lpad_plsql
8 from dual;
9 /
from dual
*
ERROR at line 8:
ORA-06502: PL/SQL: numeric or value error: character string buffer too small
ORA-06512: at line 5
SQL> @trace_pl_last.sql
RUNID EVENT_SEQ EVENT_COMMENT EVENT_UNIT_OWNER EVENT_UNIT
———- ———- ——————————– —————— ———–
1 1 PL/SQL Trace Tool started
1 2 Trace flags changed
1 3 PL/SQL Virtual Machine started <anonymous>
1 4 PL/SQL Internal Call <anonymous>
1 5 PL/SQL Virtual Machine stopped
[/sourcecode]
[collapse]
Test 2
[sourcecode language=”sql”]
SQL> @trace_pl_on
Session altered.
SQL> create or replace function f_standalone(p varchar2) return varchar2 is
2 begin
3 return lpad(‘x’,3)||p;
4 end;
5 /
Function created.
SQL> with
2 function blabla(p_str varchar2) return varchar2 is
3 s varchar2(32767);
4 begin
5 s:= lpad(p_str, 100, ‘1’);
6 s:= s||s;
7 s:= s||lpad(p_str, 100, ‘3’);
8 s:= s||s;
9 s:= s||(1+10);
10 s:= f_standalone(s);
11 s:= f_standalone(s);
12 s:= f_standalone(s);
13 return s;
14 end;
15 select
16 length(blabla(dummy)) lpad_plsql
17 from dual
18 /
LPAD_PLSQL
———-
611
SQL> @trace_pl_last.sql
RUNID EVENT_SEQ EVENT_COMMENT EVENT_UNIT_OWNER EVENT_UNIT
———- ———- ——————————– —————– ————
2 1 PL/SQL Trace Tool started
2 2 Trace flags changed
2 3 PL/SQL Virtual Machine started <anonymous>
2 4 PL/SQL Internal Call <anonymous>
2 5 PL/SQL Virtual Machine stopped
2 6 PL/SQL Virtual Machine started <anonymous>
2 7 PL/SQL Virtual Machine started <anonymous>
2 8 PL/SQL Internal Call <anonymous>
2 9 PL/SQL Virtual Machine stopped
2 10 PL/SQL Virtual Machine stopped
2 11 PL/SQL Virtual Machine started <anonymous>
2 12 PL/SQL Virtual Machine started <anonymous>
2 13 PL/SQL Internal Call <anonymous>
2 14 PL/SQL Virtual Machine stopped
2 15 PL/SQL Virtual Machine stopped
2 16 PL/SQL Virtual Machine started <anonymous>
2 17 PL/SQL Internal Call <anonymous>
2 18 PL/SQL Internal Call <anonymous>
2 19 Procedure Call <anonymous>
2 20 PL/SQL Internal Call XTENDER F_STANDALONE
2 21 Return from procedure call XTENDER F_STANDALONE
2 22 Procedure Call <anonymous>
2 23 PL/SQL Internal Call XTENDER F_STANDALONE
2 24 Return from procedure call XTENDER F_STANDALONE
2 25 Procedure Call <anonymous>
2 26 PL/SQL Internal Call XTENDER F_STANDALONE
2 27 Return from procedure call XTENDER F_STANDALONE
2 28 PL/SQL Virtual Machine stopped
28 rows selected.
[/sourcecode]
[collapse]
Test 3
[sourcecode language=”sql”]
SQL> @trace_pl_on
Session altered.
SQL> with
2 function blabla(p_str varchar2) return varchar2 is
3 s varchar2(32767);
4 begin
5 s:= lpad(p_str, 100, ‘1’);
6 s:= s||s;
7 s:= s||lpad(p_str, 100, ‘3’);
8 s:= s||s;
9 s:= s||(1+10);
10 return s;
11 end;
12 select
13 length(blabla(dummy)) lpad_plsql
14 from dual
15 /
LPAD_PLSQL
———-
602
1 row selected.
SQL> @trace_pl_last.sql
RUNID EVENT_SEQ EVENT_COMMENT EVENT_UNIT_OWNER EVENT_UNIT
———- ———- ——————————– —————— ————
3 1 PL/SQL Trace Tool started
3 2 Trace flags changed
3 3 PL/SQL Virtual Machine started <anonymous>
3 4 PL/SQL Internal Call <anonymous>
3 5 PL/SQL Internal Call <anonymous>
3 6 PL/SQL Virtual Machine stopped
6 rows selected.
[/sourcecode]
[collapse]
3. How IDENTITY works?
For all identity columns Oracle creates a sequence with name like “ISEQ$$_XXX”, where “XXX” is the object_id of the table. All identities we can get through DBA_TAB_IDENTITY_COLS.
All Identity sequences:
select i.*
,tab.owner tab_owner
,tab.object_name tab_name
,sq.object_name sequence_name
from sys.idnseq$ i
,dba_objects tab
,dba_objects sq
where tab.object_id=i.obj#
and sq.object_id = i.seqobj#
And we can see usage of this sequence in plans:
[sourcecode language=”sql”]
SQL_ID fn5tjw6hu0dtn, child number 0
————————————-
insert into xt_identity (description) values(‘1’)
Plan hash value: 3838626111
————————————————————————————————–
| Id | Operation | Name | Starts | Cost | A-Rows | A-Time | Buffers |
————————————————————————————————–
| 0 | INSERT STATEMENT | | 1 | 1 | 0 |00:00:00.01 | 35 |
| 1 | LOAD TABLE CONVENTIONAL | | 1 | | 0 |00:00:00.01 | 35 |
| 2 | SEQUENCE | ISEQ$$_91720 | 1 | | 1 |00:00:00.01 | 4 |
————————————————————————————————–
[/sourcecode]
[collapse]
4. When executes “default seq.nextval”?
Test
[sourcecode language=”sql”]
SQL> create sequence xt_sq1;
SQL> create sequence xt_sq2;
SQL> create table xt_default(
2 id1 int default xt_sq1.nextval
3 , pad varchar2(30)
4 , id2 int default xt_sq2.nextval
5 );
Table created.
SQL> insert into xt_default(pad) values(‘1’);
1 row created.
SQL> select xt_sq1.currval, xt_sq2.currval from dual;
CURRVAL CURRVAL
———- ———-
1 1
SQL> insert into xt_default(pad) values(1/0);
insert into xt_default(pad) values(1/0)
*
ERROR at line 1:
ORA-01476: divisor is equal to zero
SQL> select xt_sq1.currval, xt_sq2.currval from dual;
CURRVAL CURRVAL
———- ———-
2 2
[/sourcecode]
[collapse]
Oracle 12c: Extended varchars
Tim Hall perfectly describes in his excellent post how new extended datatypes are stored on Oracle 12c.
I just found interesting parameter “_scalar_type_lob_storage_threshold“ – “threshold for VARCHAR2, NVARCHAR2, and RAW storage as BLOB” – This parameter is the max size in bytes, at which these data types will be stored “inline” as simple datatypes, without creation of the lob segments.
See little example:
Controlling store extended varchars as lob
[sourcecode language=”sql” highlight=”5,15,20,28,54″]
SQL> @param_ _scalar_type_lob_storage_threshold;
NAME VALUE DEFLT TYPE DESCRIPTION
—————————————- ———— ———— ———— ————————————————————
_scalar_type_lob_storage_threshold 4000 TRUE number threshold for VARCHAR2, NVARCHAR2, and RAW storage as BLOB
SQL> select * from user_lobs;
no rows selected
SQL> create table T_4000(
2 i int generated always as identity
3 ,v1000 varchar2(1000)
4 ,v4000 varchar2(4000)
5 ,v4500 varchar2(4500)
6 );
Table created.
SQL> alter system set "_scalar_type_lob_storage_threshold"=5000;
System altered.
SQL> create table T_5000(
2 i int generated always as identity
3 ,v1000 varchar2(1000)
4 ,v4000 varchar2(4000)
5 ,v4500 varchar2(4500)
6 );
Table created.
SQL> select table_name,column_name ,data_type,data_type_mod,data_length,char_col_decl_length,char_length,char_used
2 from user_tab_columns;
TABLE_NAME COLUMN_NAM DATA_TYPE DAT DATA_LENGTH CHAR_COL_DECL_LENGTH CHAR_LENGTH C
———- ———- ———- — ———– ——————– ———– –
T_4000 V4500 VARCHAR2 4500 4500 4500 B
T_4000 V4000 VARCHAR2 4000 4000 4000 B
T_4000 V1000 VARCHAR2 1000 1000 1000 B
T_4000 I NUMBER 22 0
T_5000 V4500 VARCHAR2 4500 4500 4500 B
T_5000 V4000 VARCHAR2 4000 4000 4000 B
T_5000 V1000 VARCHAR2 1000 1000 1000 B
T_5000 I NUMBER 22 0
8 rows selected.
SQL> select table_name,column_name,chunk,retention,cache,logging,encrypt,compression,deduplication,in_row,securefile
2 from user_lobs;
TABLE_NAME COLUMN_NAM CHUNK RETENTION CACHE LOGGING ENCR COMPRE DEDUPLICATION IN_ SEC
———- ———- ———- ———- ———- ——- —- —— ————— — —
T_4000 V4500 8192 YES YES NO NO NO YES YES
[/sourcecode]
[collapse]
Note that there are no lobs for table t_5000!
Oracle 12c: Lateral, row_limiting_clause
Previously i showed how we can optimize getting TopN rows sorted by field “B” for each distinct value “A” with undocumented “lateral” in previous versions of Oracle RDBMS.
But now it is documented!
Very simple example:
with t as (select level a from dual connect by level&lt;=10)
select *
from t
,lateral(
select *
from dba_objects o
where object_id=t.a
)
;
Moreover, we can make now this optimization more stable and simple with row_limiting_clause:
With row_limiting_clause and multiset:
[sourcecode language=”sql”]
with t_unique( a ) as (
select min(t1.a)
from xt_test t1
union all
select (select min(t1.a) from xt_test t1 where t1.a&gt;t.a)
from t_unique t
where a is not null
)
select/*+ use_nl(rids tt) */ *
from t_unique v
,table(
cast(
multiset(
select/*+ index_desc(tt ix_xt_test_ab) */ tt.rowid rid
from xt_test tt
where tt.a=v.a
order by tt.b desc
fetch first 5 rows only
)
as sys.odcivarchar2list
)
) rids
,xt_test tt
where tt.rowid=rids.column_value
order by tt.a,tt.b desc
[/sourcecode]
[collapse]
With row_limiting_clause and lateral:
[sourcecode language=”sql”]
with t_unique( a ) as (
select min(t1.a)
from xt_test t1
union all
select next_a
from t_unique t, lateral(select min(t1.a) next_a from xt_test t1 where t1.a&gt;t.a) r
where t.a is not null
)
select/*+ use_nl(v r t) leading(v r t) */ t.*
from t_unique v
,lateral(
select/*+ index_desc(tt ix_xt_test_ab) */ rowid rid
from xt_test tt
where tt.a=v.a
order by b desc
fetch first 5 rows only
) r
,xt_test t
where r.rid=t.rowid
[/sourcecode]
[collapse]
Unfortunately, the recursive_subquery_clause with scalar subqueries sometimes doesn’t work:
Spoiler
[sourcecode language=”sql”]
SQL> with t_unique( a ) as (
2 select min(t1.a)
3 from xt_test t1
4 union all
5 select (select min(t1.a) from xt_test t1 where t1.a&gt;t.a)
6 from t_unique t
7 where a is not null
8 )
9 select/*+ use_nl(v r) */ *
10 from t_unique v
11 ,lateral(
12 select/*+ index_desc(tt ix_xt_test_ab) */ tt.*
13 from xt_test tt
14 where tt.a=v.a
15 order by tt.a, b desc
16 fetch first 5 rows only
17 ) r
18 order by r.a,r.b desc;
from xt_test t1
*
ERROR at line 3:
ORA-00600: internal error code, arguments: [qctcte1], [0], [], [], [], [], [], [], [], [], [], []
[/sourcecode]
[collapse]
But I think oracle will fix it soon, because this ORA-600 can be solved easily with hint “materialize”, but it’s not so good:
Spoiler
[sourcecode language=”sql”]
SQL> with t_unique( a ) as (
2 select min(t1.a)
3 from xt_test t1
4 union all
5 select (select min(t1.a) from xt_test t1 where t1.a&gt;t.a)
6 from t_unique t
7 where a is not null
8 ), v as (
9 select–+ materialize
10 *
11 from t_unique
12 )
13 select/*+ use_nl(v r) */ *
14 from v
15 ,lateral(
16 select/*+ index_desc(tt ix_xt_test_ab) */ tt.*
17 from xt_test tt
18 where tt.a=v.a
19 order by tt.a, b desc
20 fetch first 5 rows only
21 ) r
22 order by r.a,r.b desc;
150 rows selected.
Elapsed: 00:00:01.01
Statistics
———————————————————-
10 recursive calls
8 db block gets
11824 consistent gets
1 physical reads
624 redo size
4608 bytes sent via SQL*Net to client
462 bytes received via SQL*Net from client
11 SQL*Net roundtrips to/from client
64 sorts (memory)
0 sorts (disk)
150 rows processed
[/sourcecode]
[collapse]
UPDATE: There is a better solution:
Spoiler
[sourcecode language=”sql” highlight=”11″]
SQL> with t_unique( a ) as (
2 select min(t1.a)
3 from xt_test t1
4 union all
5 select (select min(t1.a) from xt_test t1 where t1.a&gt;t.a)
6 from t_unique t
7 where a is not null
8 ), v as (
9 select * from t_unique
10 union all
11 select null from dual where 1=0 — &lt;&lt;– workaround
12 )
13 select/*+ use_nl(v r) */ *
14 from v
15 ,lateral(
16 select/*+ index_desc(tt ix_xt_test_ab) */ tt.*
17 from xt_test tt
18 where tt.a=v.a
19 order by tt.a, b desc
20 fetch first 5 rows only
21 ) r
22 order by r.a,r.b desc;
[/sourcecode]
[collapse]
And note that we can’t use now row_limiting_clause in cursor’s:
cursor(...row_limiting_clause)
[sourcecode language=”sql”]
SQL> with
2 t_unique( a ) as (
3 select min(t1.a)
4 from xt_test t1
5 union all
6 select next_a
7 from t_unique t, lateral(select min(t1.a) next_a from xt_test t1 where t1.a&gt;t.a) r
8 where t.a is not null
9 )
10 select
11 cursor(
12 select *
13 from xt_test t
14 where t.a=v.a
15 order by a,b desc
16 fetch first 5 rows only
17 ) c
18 from t_unique v
19 ;
with
*
ERROR at line 1:
ORA-03001: unimplemented feature
ORA-00600: internal error code, arguments: [kokbcvb1], [], [], [], [], [], [], [], [], [], [], []
[/sourcecode]
[collapse]
And, just for fun, with inline pl/sql function(inconsistent):
[sourcecode language=”sql”]
SQL> with
2 function f(v_a int)
3 return sys.ku$_vcnt
4 as
5 res sys.ku$_vcnt;
6 begin
7 select tt.rowid as rid
8 bulk collect into res
9 from xt_test tt
10 where tt.a = v_a
11 order by a,b desc
12 fetch first 5 rows only;
13 return res;
14 end;
15
16 t_unique( a ) as (
17 select min(t1.a)
18 from xt_test t1
19 union all
20 select next_a
21 from t_unique t, lateral(select min(t1.a) next_a from xt_test t1 where t1.a&gt;t.a) r
22 where t.a is not null
23 )
24 select/*+ use_nl(v r t) leading(v r t) */ t.*
25 from t_unique v
26 ,table(f(v.a)) r
27 ,xt_test t
28 where r.column_value=t.rowid;
29 /
150 rows selected.
Elapsed: 00:00:00.06
Statistics
———————————————————-
31 recursive calls
0 db block gets
173 consistent gets
0 physical reads
0 redo size
5657 bytes sent via SQL*Net to client
642 bytes received via SQL*Net from client
11 SQL*Net roundtrips to/from client
32 sorts (memory)
0 sorts (disk)
150 rows processed
[/sourcecode]
[collapse]
Oracle 12c: Inconsistency of Inline “with” functions
I was hoping that if inline “with” functions are in the query, so their results will be consistent with it (as operators), but unfortunately such functions returns also inconsistent results as standalone pl/sql functions.
SQL> create table t as select 1 a from dual;
Table created.
SQL> declare
2 j binary_integer;
3 begin
4 dbms_job.submit( j
5 ,'begin
6 for i in 1..10 loop
7 dbms_lock.sleep(1);
8 update t set a=a+1;
9 commit;
10 end loop;
11 end;'
12 );
13 commit;
14 end;
15 /
PL/SQL procedure successfully completed.
SQL> with
2 function f return int is
3 res int;
4 begin
5 dbms_lock.sleep(1);
6 select a into res from t;
7 return res;
8 end;
9 select
10 f
11 from dual
12 connect by level<=10;
13 /
F
----------
1
1
1
2
3
4
5
6
7
8
10 rows selected.
Interesting: Jonathan Lewis wrote that inline “deterministic” functions doesn’t use caching mechanism as standalone deterministic functions.
Too many function executions in simple query
Suppose we have a table with 10 rows:
SQL> select id from t10;
ID
----------
1
2
3
4
5
6
7
8
9
10
10 rows selected.
And we have the query:
select *
from (
select xf(t10.id) a
from t10
)
where a*a >= 25
At first it may seem that the function should be executed as many times as rows in a table T10, i.e. 10 times.
Lets test it:
SQL> create or replace function xf(p int) return int as
2 begin
3 dbms_output.put_line('F fired!');
4 return p;
5 end;
6 /
Function created.
SQL> set serverout on;
SQL> select *
2 from (
3 select xf(t10.id) a
4 from t10
5 )
6 where a*a >= 25
7 /
A
----------
5
6
7
8
9
10
6 rows selected.
F fired!
F fired!
F fired!
F fired!
F fired! -- 5
F fired!
F fired!
F fired!
F fired!
F fired! -- 10
F fired!
F fired!
F fired!
F fired!
F fired! -- 15
F fired!
F fired!
F fired!
F fired!
F fired! -- 20
F fired!
F fired!
F fired!
F fired!
F fired! -- 25
F fired!
As you see, there are more than 10 executions, so lets see the execution plan:
SQL> @xplan +projection
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------
Plan hash value: 2919944937
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T10 | 1 | 3 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("XF"("T10"."ID")*"XF"("T10"."ID")>=25)
Column Projection Information (identified by operation id):
-----------------------------------------------------------
1 - "T10"."ID"[NUMBER,22]
Now you see that inner view was merged, and the function was executed 20 times in the filter and 6 times on the fetch after filtering(6 rows – 6 calls).
I see that often in such cases “no_merge” hint is suggested, but let’s test it:
SQL> select *
2 from (
3 select/*+ no_merge */ xf(t10.id) a
4 from t10
5 )
6 where a*a >= 25
7 /
A
----------
5
6
7
8
9
10
6 rows selected.
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
F fired!
As you can see, the number of function calls wasn’t changed.
And if we look into the plan, we understood why:
SQL> @xplan +projection
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------
Plan hash value: 2027387203
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 13 | 3 (0)| 00:00:01 |
| 1 | VIEW | | 1 | 13 | 3 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| T10 | 1 | 3 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("XF"("T10"."ID")*"XF"("T10"."ID")>=25)
Column Projection Information (identified by operation id):
-----------------------------------------------------------
1 - "A"[NUMBER,22]
2 - "T10"."ID"[NUMBER,22]
20 rows selected.
Now you see, that main problem is the “filter pushdown” transformation. Previously, if we were to disable the “filter pushdown” operation, we had to use a variety of tricks, such as “materialize” hint or adding the “rownum” in expession, etc. But all these solutions require rewriting the query.
But from 11.2.0.3 we can use “_optimizer_filter_pushdown” parameter, for example:
SQL> begin
2 dbms_sqltune.import_sql_profile(
3 sql_text => 'select * from (select xf(t10.id) a from t10) where a*a >= 25'
4 ,profile => sys.sqlprof_attr(
5 q'[NO_MERGE(@SEL$2)]'
6 ,q'[OPT_PARAM('_OPTIMIZER_FILTER_PUSHDOWN' 'FALSE')]'
7 )
8 ,category => 'DEFAULT'
9 ,name => 'TEST_PROFILE'
10 ,force_match => true
11 ,replace => true
12 );
13 end;
14 /
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.16
SQL> set serverout on
SQL> select * from (select xf(t10.id) a from t10) where a*a >= 25;
A
----------
5
6
7
8
9
10
6 rows selected.
F fired!
F fired!
F fired!
F fired!
F fired! -- 5
F fired!
F fired!
F fired!
F fired!
F fired! -- 10
F fired! -- extra execution because of sql*plus
Elapsed: 00:00:00.17
-- there are no extra calls when we fetches by 100 rows in pl/sql:
SQL> exec for r in (select * from (select xf(t10.id) a from t10) where a*a >= 25) loop null; end loop;
F fired!
F fired!
F fired!
F fired!
F fired! -- 5
F fired!
F fired!
F fired!
F fired!
F fired! -- 10
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.22
With changing arraysize
[sourcecode language=”sql”]
— with fetching by 1 row:
SQL> declare
2 cursor c is select * from (select xf(t10.id) a from t10) where a*a >= 25;
3 n number;
4 begin
5 open c;
6 loop
7 fetch c into n;
8 exit when c%notfound;
9 end loop;
10 end;
11 /
F fired!
F fired!
F fired!
F fired!
F fired! — 5
F fired!
F fired!
F fired!
F fired!
F fired! — 10
F fired!
F fired!
F fired!
F fired!
F fired! — 15
F fired!
F fired!
F fired!
F fired!
F fired! — 20
F fired!
F fired! — 22
PL/SQL procedure successfully completed.
— with arraysize = 3
SQL> set arraysi 3
SQL> select * from (select xf(t10.id) a from t10) where a*a >= 25;
A
———-
5
6
7
8
9
10
6 rows selected.
F fired!
F fired!
F fired!
F fired!
F fired! — 5
F fired!
F fired!
F fired!
F fired!
F fired! — 10
F fired!
F fired!
F fired!
F fired! — 14
Elapsed: 00:00:00.45
SQL> set arraysi 2
SQL> select * from (select xf(t10.id) a from t10) where a*a >= 25;
A
———-
5
6
7
8
9
10
6 rows selected.
F fired!
F fired!
F fired!
F fired!
F fired! — 5
F fired!
F fired!
F fired!
F fired!
F fired! — 10
F fired!
F fired!
F fired!
F fired!
F fired!
F fired! — 16
Elapsed: 00:00:00.72
[/sourcecode]
[collapse]
PS. I found that about “_optimizer_filter_pushdown” parameter already wrote Randolf Geist
A couple of well-known but often forgotten things for PL/SQL developers
1. Don’t forget always add NO_DATA_FOUND exception handling, when you doing “select into” in code which can be called as from PL/SQL, as from SQL.
A little example:
Suppose we need to create a function, which would call some procedure:
create or replace procedure p_nested as a int; begin select 1 into a from dual where 1=0; end; / create or replace function f_no_data_found return varchar2 as begin p_nested; return 'ok'; end; /
When we call this function in PL/SQL, it will raise NO_DATA_FOUND and we will see it:
SQL> exec dbms_output.put_line(f_no_data_found); BEGIN dbms_output.put_line(f_no_data_found); END; * ERROR at line 1: ORA-01403: no data found ORA-06512: at "XTENDER.P_NESTED", line 4 ORA-06512: at "XTENDER.F_NO_DATA_FOUND", line 3 ORA-06512: at line 1
But it doesn’t when we call it in SQL, because it’s normal for SQL: it’s just like a result of scalar subquery that returns nothing – NULL:
SQL> set null "NUL" SQL> col ndf format a10 SQL> select f_no_data_found ndf from dual; NDF ---------- NUL 1 row selected.
So if you want the function to behave the same way in PL/SQL and SQL, just add exception handling with reraising another exception or just return null.
It must be at the level of reflexes – “select into” → “exception when no_data_found”
Otherwise, later, when code become a big and difficult, you can get unstable hidden error.
2. Exceptions raised in a declaration section or in default parameters assigning will never be handled in exception section of the same level
Let’s take a look at a very simple example:
An example of exception in default parameter assigning
[sourcecode language=”sql”]
SQL> create or replace function f_value_error return int is
2 begin
3 raise value_error;
4 return 1;
5 end;
6 /
Function created.
SQL> create or replace function f(i int:=f_value_error) return varchar2 is
2 begin
3 return ‘ok’;
4 exception when others then
5 return dbms_utility.format_error_backtrace;
6 end;
7 /
Function created.
SQL> set serverout on;
SQL> begin
2 dbms_output.put_line(‘From f: ‘||chr(10)||f);
3 dbms_output.put_line(‘****************************’);
4 exception when others then
5 dbms_output.put_line(‘****************************’);
6 dbms_output.put_line(‘From higher level:’||chr(10)||dbms_utility.format_error_backtrace);
7 dbms_output.put_line(‘****************************’);
8 end;
9 /
****************************
From higher level:
ORA-06512: at "XTENDER.F_VALUE_ERROR", line 3
ORA-06512: at line 2
****************************
PL/SQL procedure successfully completed.
[/sourcecode]
[collapse]
As you can see, there are two problems:
1. an exception was handled at higher level
2. the error backtrace does not show the call of the function “F”.
If the exception was caused in the declaration, we would see the “correct” backtrace, but exception would be still handled at higher level only:
In the declaration
[sourcecode language=”sql” highlight=”25″]
SQL> create or replace function f(i int:=null) return varchar2 is
2 l_i int:=nvl(i,f_value_error);
3 begin
4 return ‘ok’;
5 exception when others then
6 return dbms_utility.format_error_backtrace;
7 end;
8 /
Function created.
SQL> set serverout on;
SQL> begin
2 dbms_output.put_line(‘From f: ‘||chr(10)||f);
3 dbms_output.put_line(‘****************************’);
4 exception when others then
5 dbms_output.put_line(‘****************************’);
6 dbms_output.put_line(‘From higher level:’||chr(10)||dbms_utility.format_error_backtrace);
7 dbms_output.put_line(‘****************************’);
8 end;
9 /
****************************
From higher level:
ORA-06512: at "XTENDER.F_VALUE_ERROR", line 3
ORA-06512: at "XTENDER.F", line 2
ORA-06512: at line 2
****************************
PL/SQL procedure successfully completed.
[/sourcecode]
[collapse]
Sometimes it’s not so dangerous, but last week I was investigating a complex case for this reason: one function when called in SQL throws strange exception, but in PL/SQL it works fine.
The exception was:
SQL> select PKG1.F(1,0,0,1275) from dual;
select PKG1.F(1,0,0,1275) from dual
*
ERROR at line 1:
ORA-06553: PLS-801: internal error [1401]
And the function has many functions calls in default parameters initialization, so I couldn’t even find out which one contains a root problem.
SQL*Plus tips #6: Colorizing output
If you have seen a colored scripts like a fish from “Session Snapper v.4” by Tanel Poder or OraLatencyMap by Luca Canali, you may be also want to colorize your scripts.
I’ve created the script for this purposes with a set of predefined substitution variables.
Just download colors.sql and try this script:
@colors.sql;
prompt ::: &_C_RED *** TEST PASSED *** &_C_RESET :::
prompt ::: &_C_RED *** &_C_BLINK TEST PASSED &_C_BLINK_OFF *** &_C_RESET :::
You will get something like this: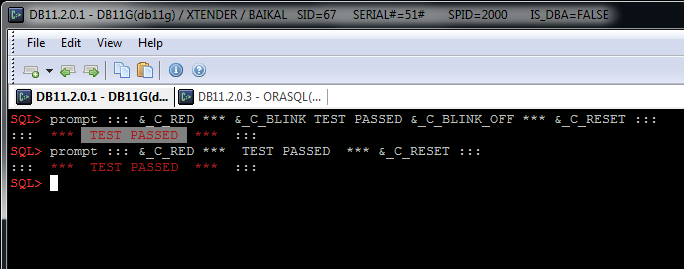
All these variables have a prefix “_C” and “_CB” for background colors.
Do not forget to close text attributes, for example: &_C_BOLD; bold text &_C_BOLD_OFF; enables “bold” attribute and disables it after “bold text”.
Full list of the predefined variables:
Predefined variables
| Description | Variable |
|---|---|
| _C_RESET | Reset formatting – Turn off all attributes |
| _C_BOLD _C_BOLD_OFF |
Set bright mode on/off |
| _C_UNDERLINE _C_UNDERLINE_OFF |
Set underline mode on/off |
| _C_BLINK _C_BLINK_OFF |
Set blink mode on/off |
| _C_REVERSE _C_REVERSE_OFF |
Exchange foreground and background colors |
| _C_HIDE _C_HIDE_OFF |
Hide text (foreground color would be the same as background) |
| _C_BLACK _C_RED _C_GREEN _C_YELLOW _C_BLUE _C_MAGENTA _C_CYAN _C_WHITE _C_DEFAULT |
Font colors |
| _CB_BLACK _CB_RED _CB_GREEN _CB_YELLOW _CB_BLUE _CB_MAGENTA _CB_CYAN _CB_WHITE _CB_DEFAULT |
Background colors |
[collapse]
In addition, I want to show a simple example of printing histograms.
We can print a simple histogram using the following query:
-- loading colors variables:
@inc/colors;
-- set max length of bar:
def _max_length=80;
-- columns formatting:
col bar format a&_max_length;
-- clear screen:
prompt &_CLS
with t as (-- it's just a test values for example:
select level id
, round(dbms_random.value(1,100)) val
from dual
connect by level<=10
)
select t.*
-- bar length is just " (value / max_value) * max_length" in symbols:
,floor( val * &_max_length / max(val)over()
) as bar_length
-- generating of bar:
,lpad( chr(176)
,ceil(val * &_max_length / max(val)over())
,chr(192)
) as bar
from t;
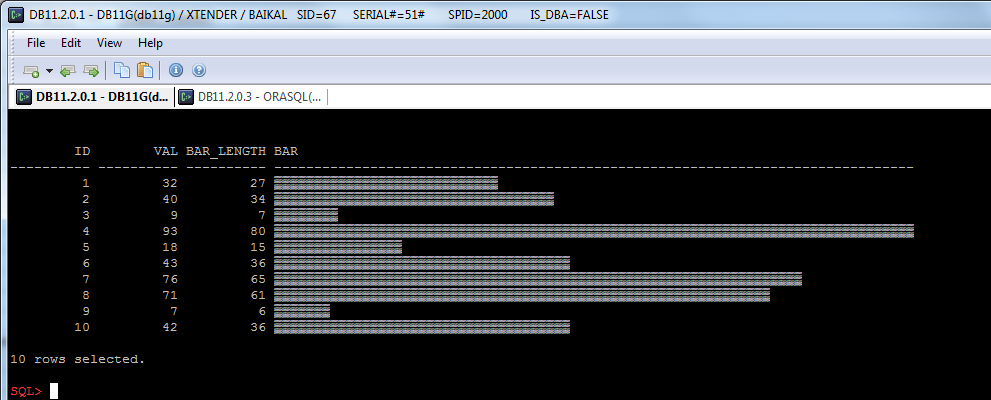
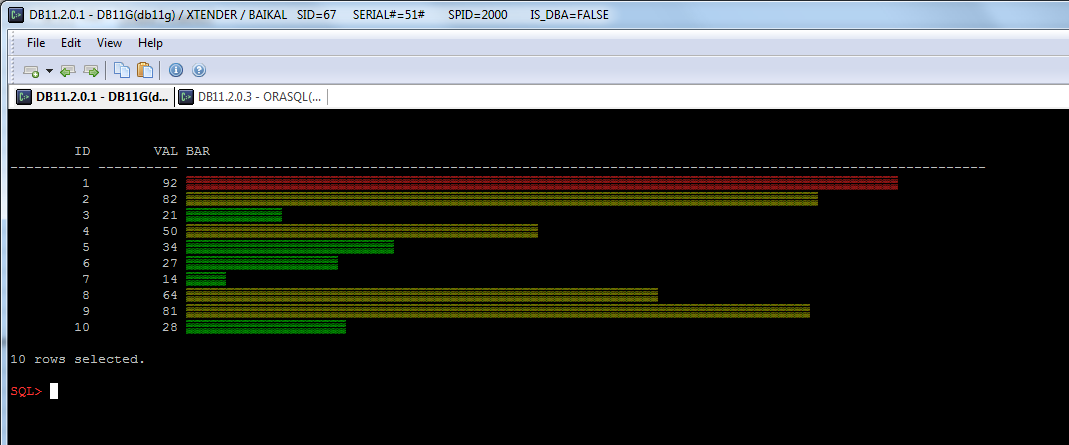
And now we can colorize it:
Colorized script
[sourcecode language="sql"]
-- loading colors variables:
@inc/colors;
-- set max length of bar:
def _max_length=100;
-- column formatting
col bar format a&amp;_max_length;
-- clear screen:
prompt &amp;_CLS
-- test query which prints histogram(or may be simply bars?):
with t as (-- it's just a test values for example:
select level id
, round(dbms_random.value(1,100)) val
from dual
connect by level&lt;=10
)
select
id
,val
, case
when pct &gt;= 0.9 then '&amp;_C_RED'
when pct &lt;= 0.4 then '&amp;_C_GREEN'
else '&amp;_C_YELLOW'
end
-- string generation:
||lpad( chr(192)
,ceil(pct * &amp;_max_length)-9 -- color - 5 chars and reset - 4
,chr(192)
)
||'&amp;_C_RESET'
as bar
from (
select
t.*
,val / max(val)over() as pct -- as a percentage of max value:
from t
) t2
/
[/sourcecode]
[collapse]
SQL*Plus tips #5: sql_text/sql_fulltext formatting(sql beatifier)
Sometimes I get tired of watching unformatted query text from v$sqlarea, dba_hist_sqltext in SQL*Plus, so I decided to include automatic query formatting in my scripts.
I thought that there are many libraries for such purposes on languages which i know, and it’s true, but it turned out that many of them are not appropriate for Oracle.
So I took the most appropriate – perl module SQL::Beautify and corrected it. Now i can share my first solution.
How it looks:
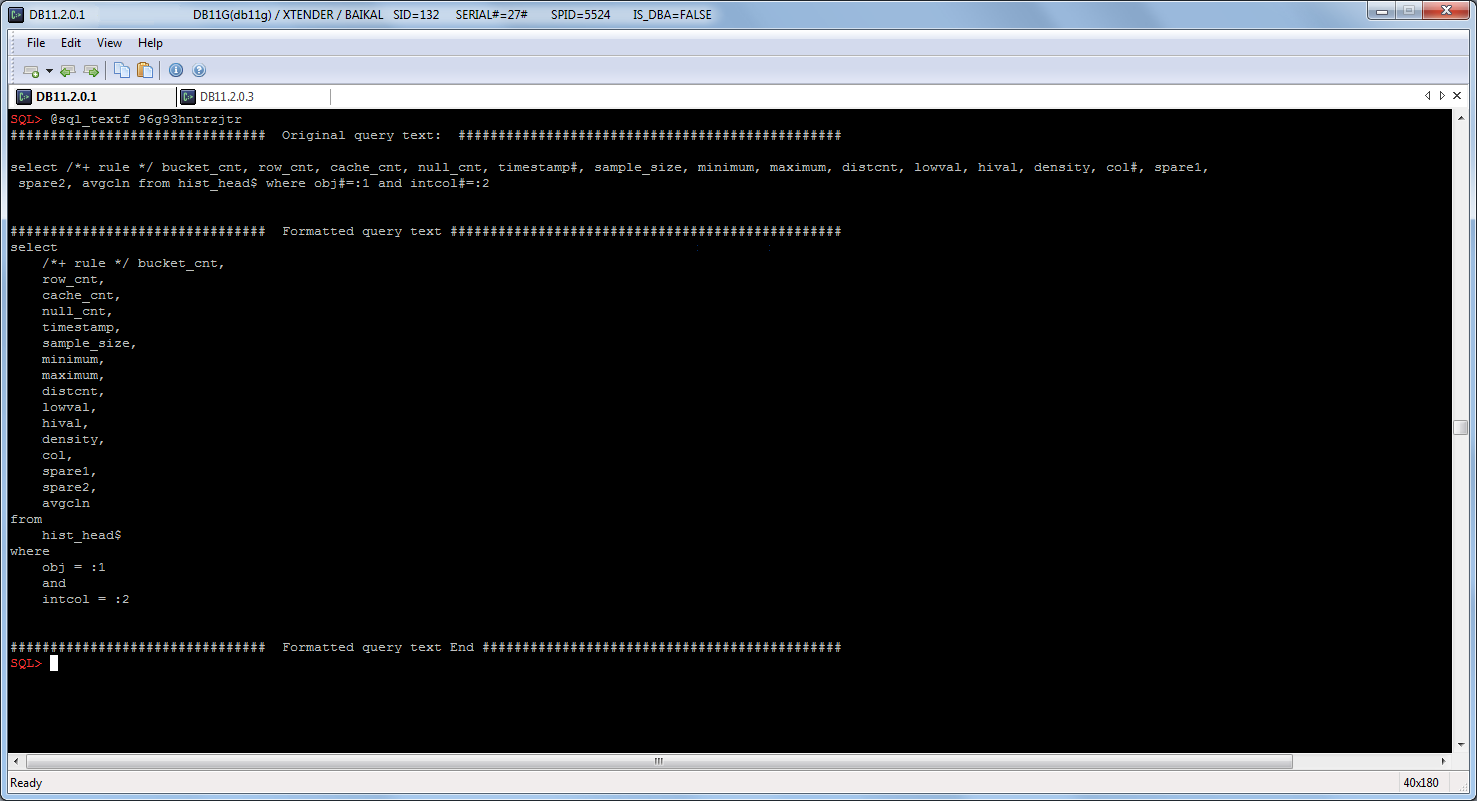
What you need to do it:
1. If you on Windows and you have not install Oracle RDBMS or cygwin, you need to install perl. It can be done for example with ActivePerl or StrawberryPerl, but i recommend cygwin
2. You need to save sql_format_standalone.pl within $SQL_PATH/inc directory.
inc/sql_format_standalone.pl
[sourcecode language=”sql”]
package OraTokenizer;
use warnings;
use strict;
use 5.006002;
use Exporter;
our @ISA = qw(Exporter);
our @EXPORT_OK= qw(tokenize_sql);
our $VERSION= ‘0.24’;
my $re= qr{
(
(?:–)[\ \t\S]* # single line comments
|
(?:<>|<=>|>=|<=|==|=|!=|!|<<|>>|<|>|\|\||\||&&|&|-|\+|\*(?!/)|/(?!\*)|\%|~|\^|\?)
# operators and tests
|
\(\+\)
# oracle join
|
[\[\]\(\),;.] # punctuation (parenthesis, comma)
|
\’\'(?!\’) # empty single quoted string
|
\"\"(?!\"") # empty double quoted string
|
"(?>(?:(?>[^"\\]+)|""|\\.)*)+"
# anything inside double quotes, ungreedy
|
`(?>(?:(?>[^`\\]+)|“|\\.)*)+`
# anything inside backticks quotes, ungreedy
|
‘(?>(?:(?>[^’\\]+)|”|\\.)*)+’
# anything inside single quotes, ungreedy.
|
/\*[\ \t\r\n\S]*?\*/ # C style comments
|
(?:[\w:@]+(?:[.\$](?:\w+|\*)?)*)
# words, standard named placeholders, db.table.*, db.*
|
\n # newline
|
[\t\ ]+ # any kind of white spaces
)
}smx;
sub tokenize_sql {
my ( $query, $remove_white_tokens )= @_;
my @query= $query =~ m{$re}smxg;
if ($remove_white_tokens) {
@query= grep( !/^[\s\n\r]*$/, @query );
}
return wantarray ? @query : \@query;
}
sub tokenize {
my $class= shift;
return tokenize_sql(@_);
}
1;
=pod
=head1 NAME
OraTokenizer – A simple SQL tokenizer.
=head1 VERSION
0.20
=head1 SYNOPSIS
use OraTokenizer qw(tokenize_sql);
my $query= q{SELECT 1 + 1};
my @tokens= OraTokenizer->tokenize($query);
# @tokens now contains (‘SELECT’, ‘ ‘, ‘1’, ‘ ‘, ‘+’, ‘ ‘, ‘1’)
@tokens= tokenize_sql($query); # procedural interface
=head1 DESCRIPTION
OraTokenizer is a simple tokenizer for SQL queries. It does not claim to be
a parser or query verifier. It just creates sane tokens from a valid SQL
query.
It supports SQL with comments like:
— This query is used to insert a message into
— logs table
INSERT INTO log (application, message) VALUES (?, ?)
Also supports C<”>, C<""> and C<\’> escaping methods, so tokenizing queries
like the one below should not be a problem:
INSERT INTO log (application, message)
VALUES (‘myapp’, ‘Hey, this is a ”single quoted string”!’)
=head1 API
=over 4
=item tokenize_sql
use OraTokenizer qw(tokenize_sql);
my @tokens= tokenize_sql($query);
my $tokens= tokenize_sql($query);
$tokens= tokenize_sql( $query, $remove_white_tokens );
C<tokenize_sql> can be imported to current namespace on request. It receives a
SQL query, and returns an array of tokens if called in list context, or an
arrayref if called in scalar context.
=item tokenize
my @tokens= OraTokenizer->tokenize($query);
my $tokens= OraTokenizer->tokenize($query);
$tokens= OraTokenizer->tokenize( $query, $remove_white_tokens );
This is the only available class method. It receives a SQL query, and returns an
array of tokens if called in list context, or an arrayref if called in scalar
context.
If C<$remove_white_tokens> is true, white spaces only tokens will be removed from
result.
=back
=head1 ACKNOWLEDGEMENTS
=over 4
=item
Evan Harris, for implementing Shell comment style and SQL operators.
=item
Charlie Hills, for spotting a lot of important issues I haven’t thought.
=item
Jonas Kramer, for fixing MySQL quoted strings and treating dot as punctuation character correctly.
=item
Emanuele Zeppieri, for asking to fix OraTokenizer to support dollars as well.
=item
Nigel Metheringham, for extending the dollar signal support.
=item
Devin Withers, for making it not choke on CR+LF in comments.
=item
Luc Lanthier, for simplifying the regex and make it not choke on backslashes.
=back
=head1 AUTHOR
Copyright (c) 2007, 2008, 2009, 2010, 2011 Igor Sutton Lopes "<IZUT@cpan.org>". All rights
reserved.
This module is free software; you can redistribute it and/or modify it under
the same terms as Perl itself.
=cut
###################################
package OraBeautify;
use strict;
use warnings;
our $VERSION = 0.04;
use Carp;
# Keywords from SQL-92, SQL-99 and SQL-2003.
use constant KEYWORDS => qw(
ABSOLUTE ACTION ADD AFTER ALL ALLOCATE ALTER AND ANY ARE ARRAY AS ASC
ASENSITIVE ASSERTION ASYMMETRIC AT ATOMIC AUTHORIZATION AVG BEFORE BEGIN
BETWEEN BIGINT BINARY BIT BIT_LENGTH BLOB BOOLEAN BOTH BREADTH BY CALL
CALLED CASCADE CASCADED CASE CAST CATALOG CHAR CHARACTER CHARACTER_LENGTH
CHAR_LENGTH CHECK CLOB CLOSE COALESCE COLLATE COLLATION COLUMN COMMIT
CONDITION CONNECT CONNECTION CONSTRAINT CONSTRAINTS CONSTRUCTOR CONTAINS
CONTINUE CONVERT CORRESPONDING COUNT CREATE CROSS CUBE CURRENT CURRENT_DATE
CURRENT_DEFAULT_TRANSFORM_GROUP CURRENT_PATH CURRENT_ROLE CURRENT_TIME
CURRENT_TIMESTAMP CURRENT_TRANSFORM_GROUP_FOR_TYPE CURRENT_USER CURSOR
CYCLE DATA DATE DAY DEALLOCATE DEC DECIMAL DECLARE DEFAULT DEFERRABLE
DEFERRED DELETE DEPTH DEREF DESC DESCRIBE DESCRIPTOR DETERMINISTIC
DIAGNOSTICS DISCONNECT DISTINCT DO DOMAIN DOUBLE DROP DYNAMIC EACH ELEMENT
ELSE ELSEIF END EPOCH EQUALS ESCAPE EXCEPT EXCEPTION EXEC EXECUTE EXISTS
EXIT EXTERNAL EXTRACT FALSE FETCH FILTER FIRST FLOAT FOR FOREIGN FOUND FREE
FROM FULL FUNCTION GENERAL GET GLOBAL GO GOTO GRANT GROUP GROUPING HANDLER
HAVING HOLD HOUR IDENTITY IF IMMEDIATE IN INDICATOR INITIALLY INNER INOUT
INPUT INSENSITIVE INSERT INT INTEGER INTERSECT INTERVAL INTO IS ISOLATION
ITERATE JOIN KEY LANGUAGE LARGE LAST LATERAL LEADING LEAVE LEFT LEVEL LIKE
LIMIT LOCAL LOCALTIME LOCALTIMESTAMP LOCATOR LOOP LOWER MAP MATCH MAX
MEMBER MERGE METHOD MIN MINUTE MODIFIES MODULE MONTH MULTISET NAMES
NATIONAL NATURAL NCHAR NCLOB NEW NEXT NO NONE NOT NULL NULLIF NUMERIC
OBJECT OCTET_LENGTH OF OLD ON ONLY OPEN OPTION OR ORDER ORDINALITY OUT
OUTER OUTPUT OVER OVERLAPS PAD PARAMETER PARTIAL PARTITION PATH POSITION
PRECISION PREPARE PRESERVE PRIMARY PRIOR PRIVILEGES PROCEDURE PUBLIC RANGE
READ READS REAL RECURSIVE REF REFERENCES REFERENCING RELATIVE RELEASE
REPEAT RESIGNAL RESTRICT RESULT RETURN RETURNS REVOKE RIGHT ROLE ROLLBACK
ROLLUP ROUTINE ROW ROWS PIVOT UNPIVOT XMLTABLE XMLSEQUENCE XMLQUERY
SAVEPOINT SCHEMA SCOPE SCROLL SEARCH SECOND SECTION SEQUENCE
SELECT SENSITIVE SESSION SESSION_USER SET SETS SIGNAL SIMILAR SIZE SMALLINT
SOME SPACE SPECIFIC SPECIFICTYPE SQL SQLCODE SQLERROR SQLEXCEPTION SQLSTATE
SQLWARNING START STATE STATIC SUBMULTISET SUBSTRING SUM SYMMETRIC SYSTEM
SYSTEM_USER TABLE TABLESAMPLE TEMPORARY TEXT THEN TIME TIMESTAMP
TIMEZONE_HOUR TIMEZONE_MINUTE TINYINT TO TRAILING TRANSACTION TRANSLATE
TRANSLATION TREAT TRIGGER TRIM TRUE UNDER UNDO UNION UNIQUE UNKNOWN UNNEST
UNTIL UPDATE UPPER USAGE USER USING VALUE VALUES VARCHAR VARYING VIEW WHEN
WHENEVER WHERE WHILE WINDOW WITH WITHIN WITHOUT WORK WRITE YEAR ZONE
);
sub new {
my ($class, %options) = @_;
my $self = bless { %options }, $class;
# Set some defaults.
$self->{query} = ” unless defined($self->{query});
$self->{spaces} = 4 unless defined($self->{spaces});
$self->{space} = ‘ ‘ unless defined($self->{space});
$self->{break} = "\n" unless defined($self->{break});
$self->{wrap} = {} unless defined($self->{wrap});
$self->{keywords} = [] unless defined($self->{keywords});
$self->{rules} = {} unless defined($self->{rules});
$self->{uc_keywords} = 0 unless defined $self->{uc_keywords};
push @{$self->{keywords}}, KEYWORDS;
# Initialize internal stuff.
$self->{_level} = 0;
return $self;
}
# Add more SQL.
sub add {
my ($self, $addendum) = @_;
$addendum =~ s/^\s*/ /;
$self->{query} .= $addendum;
}
# Set SQL to beautify.
sub query {
my ($self, $query) = @_;
$self->{query} = $query if(defined($query));
return $self->{query};
}
# Beautify SQL.
sub beautify {
my ($self) = @_;
$self->{_output} = ”;
$self->{_level_stack} = [];
$self->{_new_line} = 1;
my $last;
$self->{_tokens} = [ OraTokenizer->tokenize($self->query, 1) ];
while(defined(my $token = $self->_token)) {
my $rule = $self->_get_rule($token);
# Allow custom rules to override defaults.
if($rule) {
$self->_process_rule($rule, $token);
}
elsif($token eq ‘(‘) {
$self->_add_token($token);
$self->_new_line;
push @{$self->{_level_stack}}, $self->{_level};
$self->_over unless $last and uc($last) eq ‘WHERE’;
}
elsif($token eq ‘)’) {
$self->_new_line;
$self->{_level} = pop(@{$self->{_level_stack}}) || 0;
$self->_add_token($token);
$self->_new_line;
}
elsif($token eq ‘,’) {
$self->_add_token($token);
$self->_new_line;
}
elsif($token eq ‘;’) {
$self->_add_token($token);
$self->_new_line;
# End of statement; remove all indentation.
@{$self->{_level_stack}} = ();
$self->{_level} = 0;
}
elsif($token =~ /^(?:SELECT|FROM|WHERE|HAVING)$/i) {
$self->_back unless $last and $last eq ‘(‘;
$self->_new_line;
$self->_add_token($token);
$self->_new_line if($self->_next_token and $self->_next_token ne ‘(‘);
$self->_over;
}
elsif($token =~ /^(?:GROUP|ORDER|LIMIT)$/i) {
$self->_back;
$self->_new_line;
$self->_add_token($token);
}
elsif($token =~ /^(?:BY)$/i) {
$self->_add_token($token);
$self->_new_line;
$self->_over;
}
elsif($token =~ /^(?:UNION|INTERSECT|EXCEPT)$/i) {
$self->_new_line;
$self->_add_token($token);
$self->_new_line;
}
elsif($token =~ /^(?:LEFT|RIGHT|INNER|OUTER|CROSS)$/i) {
$self->_back;
$self->_new_line;
$self->_add_token($token);
$self->_over;
}
elsif($token =~ /^(?:JOIN)$/i) {
if($last and $last !~ /^(?:LEFT|RIGHT|INNER|OUTER|CROSS)$/) {
$self->_new_line;
}
$self->_add_token($token);
}
elsif($token =~ /^(?:AND|OR)$/i) {
$self->_new_line;
$self->_add_token($token);
$self->_new_line;
}
else {
$self->_add_token($token, $last);
}
$last = $token;
}
$self->_new_line;
$self->{_output};
}
# Add a token to the beautified string.
sub _add_token {
my ($self, $token, $last_token) = @_;
if($self->{wrap}) {
my $wrap;
if($self->_is_keyword($token)) {
$wrap = $self->{wrap}->{keywords};
}
elsif($self->_is_constant($token)) {
$wrap = $self->{wrap}->{constants};
}
if($wrap) {
$token = $wrap->[0] . $token . $wrap->[1];
}
}
my $last_is_dot =
defined($last_token) && $last_token eq ‘.’;
if(!$self->_is_punctuation($token) and !$last_is_dot) {
$self->{_output} .= $self->_indent;
}
# uppercase keywords
$token = uc $token
if $self->_is_keyword($token) and $self->{uc_keywords};
$self->{_output} .= $token;
# This can’t be the beginning of a new line anymore.
$self->{_new_line} = 0;
}
# Increase the indentation level.
sub _over {
my ($self) = @_;
++$self->{_level};
}
# Decrease the indentation level.
sub _back {
my ($self) = @_;
–$self->{_level} if($self->{_level} > 0);
}
# Return a string of spaces according to the current indentation level and the
# spaces setting for indenting.
sub _indent {
my ($self) = @_;
if($self->{_new_line}) {
return $self->{space} x ($self->{spaces} * $self->{_level});
}
else {
return $self->{space};
}
}
# Add a line break, but make sure there are no empty lines.
sub _new_line {
my ($self) = @_;
$self->{_output} .= $self->{break} unless($self->{_new_line});
$self->{_new_line} = 1;
}
# Have a look at the token that’s coming up next.
sub _next_token {
my ($self) = @_;
return @{$self->{_tokens}} ? $self->{_tokens}->[0] : undef;
}
# Get the next token, removing it from the list of remaining tokens.
sub _token {
my ($self) = @_;
return shift @{$self->{_tokens}};
}
# Check if a token is a known SQL keyword.
sub _is_keyword {
my ($self, $token) = @_;
return ~~ grep { $_ eq uc($token) } @{$self->{keywords}};
}
# Add new keywords to highlight.
sub add_keywords {
my $self = shift;
for my $keyword (@_) {
push @{$self->{keywords}}, ref($keyword) ? @{$keyword} : $keyword;
}
}
# Add new rules.
sub add_rule {
my ($self, $format, $token) = @_;
my $rules = $self->{rules} ||= {};
my $group = $rules->{$format} ||= [];
push @{$group}, ref($token) ? @{$token} : $token;
}
# Find custom rule for a token.
sub _get_rule {
my ($self, $token) = @_;
values %{$self->{rules}}; # Reset iterator.
while(my ($rule, $list) = each %{$self->{rules}}) {
return $rule if(grep { uc($token) eq uc($_) } @$list);
}
return undef;
}
sub _process_rule {
my ($self, $rule, $token) = @_;
my $format = {
break => sub { $self->_new_line },
over => sub { $self->_over },
back => sub { $self->_back },
token => sub { $self->_add_token($token) },
push => sub { push @{$self->{_level_stack}}, $self->{_level} },
pop => sub { $self->{_level} = pop(@{$self->{_level_stack}}) || 0 },
reset => sub { $self->{_level} = 0; @{$self->{_level_stack}} = (); },
};
for(split /-/, lc $rule) {
&{$format->{$_}} if($format->{$_});
}
}
# Check if a token is a constant.
sub _is_constant {
my ($self, $token) = @_;
return ($token =~ /^\d+$/ or $token =~ /^([‘"`]).*\1$/);
}
# Check if a token is punctuation.
sub _is_punctuation {
my ($self, $token) = @_;
return ($token =~ /^[,;.]$/);
}
1;
=pod
=head1 NAME
OraBeautify – Beautify SQL statements by adding line breaks indentation
=head1 SYNOPSIS
my $sql = OraBeautify->new;
$sql->query($sql_query);
my $nice_sql = $sql->beautify;
=head1 DESCRIPTION
Beautifies SQL statements by adding line breaks indentation.
=head1 METHODS
=over 4
=item B<new>(query => ”, spaces => 4, space => ‘ ‘, break => "\n", wrap => {})
Constructor. Takes a few options.
=over 4
=item B<query> => ”
Initialize the instance with a SQL string. Defaults to an empty string.
=item B<spaces> => 4
Number of spaces that make one indentation level. Defaults to 4.
=item B<space> => ‘ ‘
A string that is used as space. Default is an ASCII space character.
=item B<break> => "\n"
String that is used for linebreaks. Default is "\n".
=item B<wrap> => {}
Use this if you want to surround certain tokens with markup stuff. Known token
types are "keywords" and "constants" for now. The value of each token type
should be an array with two elements, one that is placed before the token and
one that is placed behind it. For example, use make keywords red using terminal
color escape sequences.
{ keywords => [ "\x1B[0;31m", "\x1B[0m" ] }
=item B<uc_keywords> => 1|0
When true (1) all SQL keywords will be uppercased in output. Default is false (0).
=back
=item B<add>($more_sql)
Appends another chunk of SQL.
=item B<query>($query)
Sets the query to the new query string. Overwrites anything that was added with
prior calls to B<query> or B<add>.
=item B<beautify>
Beautifies the internally saved SQL string and returns the result.
=item B<add_keywords>($keyword, $another_keyword, \@more_keywords)
Add any amount of keywords of arrays of keywords to highlight.
=item B<add_rule>($rule, $token)
Add a custom formatting rule. The first argument is the rule, a string
containing one or more commands (explained below), separated by dashes. The
second argument may be either a token (string) or a list of strings. Tokens are
grouped by rules internally, so you may call this method multiple times with
the same rule string and different tokens, and the rule will apply to all of
the tokens.
The following formatting commands are known at the moment:
=over 4
=item B<token> – insert the token this rule applies to
=item B<over> – increase indentation level
=item B<back> – decrease indentation level
=item B<break> – insert line break
=item B<push> – push current indentation level to an internal stack
=item B<pop> – restore last indentation level from the stack
=item B<reset> – reset internal indentation level stack
=back
B<push>, B<pop> and B<reset> should be rarely needed.
B<NOTE>:
Custom rules override default rules. Some default rules do things that
can’t be done using custom rules, such as changing the format of a token
depending on the last or next token.
B<NOTE>:
I’m trying to provide sane default rules. If you find that a custom
rule of yours would make more sense as a default rule, please create a ticket.
=back
=head1 BUGS
Needs more tests.
Please report bugs in the CPAN bug tracker.
This module is not complete (known SQL keywords, special formatting of
keywords), so if you want see something added, just send me a patch.
=head1 COPYRIGHT
Copyright (C) 2009 by Jonas Kramer. Published under the terms of the Artistic
License 2.0.
=cut
########################################
package main;
use strict;
open (SQL, "<", $ARGV[0]) || die (‘File not found!’);
my $query = join("\n",<SQL>);
my $beautifier = OraBeautify->new;
$beautifier -> add_keywords(qw{
pivot unpivot
model dimension measures rules
xmltable xmlsequence columns});
$beautifier->query(
$query,
spaces => 4,
space => ‘ ‘,
break => "\n",
wrap => {‘$’,’$’}
);
my $nice_sql = $beautifier->beautify;
print $nice_sql ."\n";
__END__
[/sourcecode]
[collapse]
3. Create empty directory “tmp” within $SQL_PATH
4. Now you can use it for example like i did it in sql_textf.sql:
sql_textf.sql
[sourcecode language=”sql”]
set timing off head off
col qtext format a150
prompt ################################ Original query text: ################################################;
spool tmp/to_format.sql
select
coalesce(
(select sql_fulltext from v$sqlarea a where a.sql_id=’&1′)
, (select sql_text from dba_hist_sqltext a where a.sql_id=’&1′ and dbid=(select dbid from v$database))
) qtext
from dual
;
spool off
prompt ################################ Formatted query text #################################################;
host perl inc/sql_format_standalone.pl tmp/to_format.sql
prompt ################################ Formatted query text End #############################################;
set termout on head on
[/sourcecode]
[collapse]
I also use it in other scripts, like sqlid.sql:
[sourcecode language=”sql”]
@inc/input_vars_init;
REM ############### COMMON FORMATTING #######################
col SQL_ID for a13
col sql_child_number head CH# for 999
col SQL_PROFILE head PROFILE for a19
—————————————–
— params check:
set termout off timing off
def _sqlid=&1
col _child new_val _child noprint
select
case
when translate(‘&2′,’x0123456789′,’x’) is null
then nvl(‘&2′,’%’)
else ‘%’
end "_CHILD"
from dual;
—————————————–
set termout on
prompt ####################################################################################################;
prompt # Show SQL text, child cursors and execution stats for SQLID &1 child &2
prompt ####################################################################################################;
REM ################### SHOW SQL TEXT ############################
@sql_textf &_sqlid
REM ################### SHOW V$SQL ##############################
col proc_name for a30
col P_schema for a20
select
s.sql_id
,s.CHILD_NUMBER sql_child_number
,s.address parent_handle
,s.child_address object_handle
,s.PLAN_HASH_VALUE plan_hv
,s.hash_value hv
,s.SQL_PROFILE sql_profile
,decode(s.EXECUTIONS,0,0, s.ELAPSED_TIME/1e6/s.EXECUTIONS) elaexe
,s.EXECUTIONS cnt
,s.FETCHES fetches
,s.END_OF_FETCH_COUNT end_of_fetch_count
,s.FIRST_LOAD_TIME first_load_time
,s.PARSE_CALLS parse_calls
,decode(s.executions,0,0, s.DISK_READS /s.executions) disk_reads
,decode(s.executions,0,0, s.BUFFER_GETS /s.executions) buffer_gets
,decode(s.executions,0,0, s.DIRECT_WRITES /s.executions) direct_writes
,decode(s.executions,0,0, s.APPLICATION_WAIT_TIME/1e6/s.executions) app_wait
,decode(s.executions,0,0, s.CONCURRENCY_WAIT_TIME/1e6/s.executions) concurrency
,decode(s.executions,0,0, s.USER_IO_WAIT_TIME /1e6/s.executions) io_wait
,decode(s.executions,0,0, s.PLSQL_EXEC_TIME /1e6/s.executions) plsql_t
,decode(s.executions,0,0, s.java_exec_time /1e6/s.executions) java_exec_t
,s.ROWS_PROCESSED row_processed
,s.OPTIMIZER_MODE opt_mode
,s.OPTIMIZER_COST cost
,s.OPTIMIZER_ENV_HASH_VALUE env_hash
,s.PARSING_SCHEMA_NAME P_schema
,decode(s.executions,0,0, s.CPU_TIME/1e6/s.executions) CPU_TIME
,s.PROGRAM_ID
,(select object_name from dba_objects o where o.object_id=s.PROGRAM_ID) proc_name
,s.PROGRAM_LINE# proc_line
from v$sql s
where
sql_id = (‘&_sqlid’)
and child_number like ‘&_child’
order by
sql_id,
hash_value,
child_number
/
REM ##################### END V$SQL ##############################
REM ################### PLSQL OBJECT ##############################
col owner for a10
col object_name for a30
col text for a120
select
a.SQL_ID,a.SQL_PROFILE
,p.owner,p.object_name
,s.line
,rtrim(s.text,chr(10)) text
from
v$sqlarea a
left join dba_procedures p
on a.PROGRAM_ID=p.OBJECT_ID
left join dba_source s
on p.owner=s.owner
and p.OBJECT_NAME=s.name
and s.line between a.PROGRAM_LINE#-5 and a.PROGRAM_LINE#+5
where a.SQL_ID=’&_sqlid’
/
REM ################### EXECUTIONS IN SQL_MONITOR ######################
@if "’&_O_RELEASE’>’11.2’" then
col error_message for a40
@rtsm/execs "&_sqlid" "&_child"
/* end if */
REM ########################### clearing ############################
col SQL_PROFILE clear
col owner clear
col object_name clear
col text clear
col error_message clear
@inc/input_vars_undef;
[/sourcecode]
[collapse]
SQL*Plus tips #4: Branching execution
Today I’ll show a trick how we can use branching execution of SQLPlus scripts in SQL*Plus.
Although I previously showed the conditional execution of scripts and it really can be used for branching, but today I’ll show how to do it without splitting the script into several smaller scripts. In contrast to the conditional script execution, I’ll use a different method.
It is very simple, as usual – if you want to execute only one part of script, you can just comment out all unnecessary. So depending on the conditions, we can execute a script which will start a comment.
Suppose we need to create a script, which, depending on the input parameter will be required to execute a specific query.
See how this can be done:
1. “test.sql”:
def param = &1 @if ¶m=1 select 1 from dual; /* end_if */ @if ¶m=2 select 2 from dual; /* end_if */ @if ¶m=3 select 3 from dual; /* end_if */
2. “if.sql”:
col do_next new_val do_next noprint;
select
case
when &1 then 'inc/null'
else 'inc/comment_on'
end as do_next
from dual;
@&do_next
3. “inc/comment_on.sql” contains only 2 chars:
/*
4. “inc/null.sql” is the same as in the previous examples – just empty file.
Ok, lets test it:
SQL> @test 1
1
----------
1
SQL> @test 2
2
----------
2
SQL> @test 3
3
----------
3
As you see, we got what we wanted. Please note that we have to close the multiline comments in the right places only(/* end_if */). So we cannot use in these parts another “*/”. But you can use it in another child scripts.
Same way we can make an analogue of switch/case:
“test2.sql”:
@switch &1
@when 1 then
select 1 from dual;
/* end when */
@when 2 then
select 2 from dual;
/* end when */
@when 3 then
select 3 from dual;
/* end when */
/* end switch */
switch.sql
[sourcecode language=”sql”]
def switch_param=&1
[/sourcecode]
[collapse]
when.sql
[sourcecode language=”sql”]
col do_next new_val do_next noprint;
select
case
when &1 = &switch_param then ‘inc/null’
else ‘inc/comment_on’
end as do_next
from dual;
@&do_next
[/sourcecode]
[collapse]
Example:
SQL> @test2 2
2
----------
2
SQL> @test2 3
3
----------
3