
Oracle 12c introduced Partial indexing, which works well for simple partitioned tables with literals. However, it has several significant issues:
Continue readingTag Archives: oracle
Slow index access “COL=:N” where :N is NULL
All Oracle specialists know that a predicate X=NULL can never be true and we should use “X is NULL” in such cases. The Oracle optimizer knows about that, so if we create a table like this:
Continue readingWhere does the commit or rollback happen in PL/SQL code?
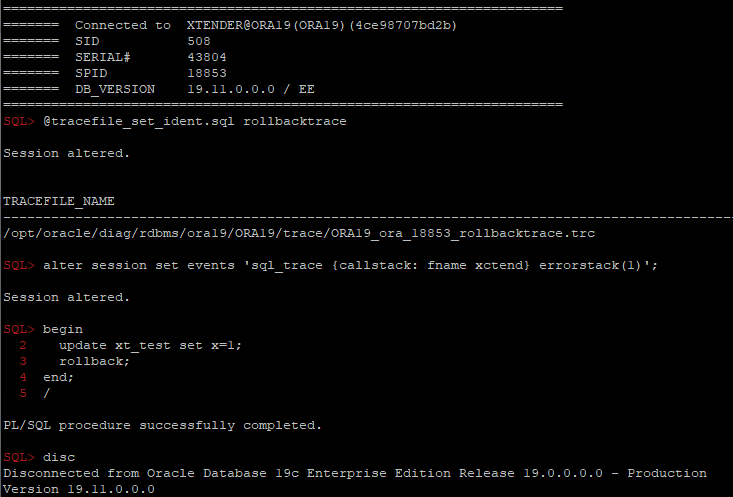
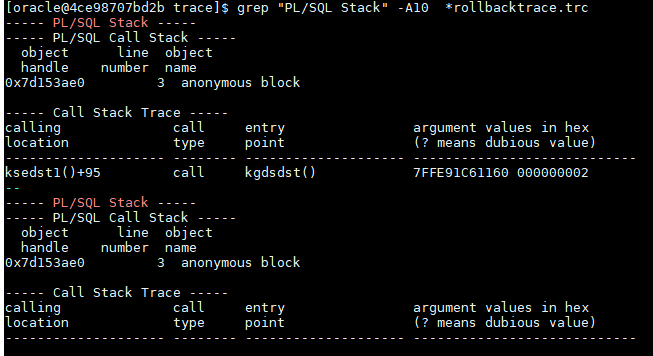
One of the easiest ways is to use diagnostic events:
alter session set events 'sql_trace {callstack: fname xctend} errorstack(1)';
ORA exceptions that can’t be caught by exception handler
I know 2 “special” exceptions that can’t be processed in exception handler:
- “ORA-01013: user requested cancel of current operation”
- “ORA-03113: end-of-file on communication channel”
- and + “ORA-00028: your session has been killed” from Matthias Rogel
Tanel Poder described the first one (ORA-01013) in details here: https://tanelpoder.com/2010/02/17/how-to-cancel-a-query-running-in-another-session/ where Tanel shows that this error is based on SIGURG signal (kill -URG):
-- 1013 will not be caught:
declare
e exception;
pragma exception_init(e,-1013);
begin
raise e;
exception when others then dbms_output.put_line('caught');
end;
/
declare
*
ERROR at line 1:
ORA-01013: user requested cancel of current operation
ORA-06512: at line 5
Oracle diagnostic events — Cheat sheet
Oracle diagnostic events is a great feature, but unfortunately poorly documented and nonintuitive, so it’s difficult to remember all events/actions/parameters and even read its internal documentation using oradebug. So I decided to compile its internal doc as a more convenient html-version (https://orasql.org/files/events/) and make a cheat sheet of some unknown or little-known use cases.
Example 1:
alter system set events
'kg_event[1476]
{occurence: start_after 1, end_after 3}
trace("stack is: %\n", shortstack())
errorstack(2)
';
- kg_event[errno] – Kernel Generic event in library Generic for error number events, which instructs to trace ORA-errno errors;
- {occurence: start_after X, end_after Y} – is a filter, which instructs to skip X event checks and trace just Y times;
- trace(format, str1, str2, …, str15) – is a function from ACTIONS for printing into a trace file;
- shortstack() – is a function from ACTIONS , which returns a short call stack as a string;
- errorstack(level) – is a function from ACTIONS, which prints extended info (level: 0 – errorstack only, 1 – errorstack + call stack, 2 – as level 1 + processtate, 3 – as level 2 + context area). You can get more details with PROCESSSTATE or SYSTEMSTATE. If you need just a call stack, you can use CALLSTACK(level) , with function arguments in case of level>1.
Example 2:
alter system set events
'trace[SQL_Compiler.* | SQL_Execution.*]
[SQL: ...]
{process: ospid = ...}
{occurence:end_after 3}
controlc_signal()';
Triaging Smart Scan
This document is my attempt to bring together the available options that can be used to determine the root cause of an issue in order to create a roadmap to help support engineers narrow down the cause of concern.
It is a living document and will be edited and amended as time goes by. Please do check back again in the future.
Warning: these parameters should only be used in conjunction with an Oracle Support Engineer and are not intended for DBAs to self-triage; also they should not be left set after triage without discussion with an Oracle Support Engineer.
Continue readingpySyncOracleStandby – Simple sync service for Oracle manual standby
I created this simple service a couple of years ago. It’s pretty simple, small and intuitive Python app, so you can easily modify it to suit your own needs and run on any platform: https://github.com/xtender/pySync
Serial Scans failing to offload
Very Large Buffer Cache
We’ve observed databases with very large buffer caches where Serial Scans don’t make use of Smart Scan when that would have executed faster: improvements to the decision making for Serial Scans have been made under bug 31626438. This fix is back-portable.
A key difference between PQ and Serial is that as part of granule generation PQ sums the sizes of all the partitions that have not been pruned and passes that total size to the buffer cache decision making logic. Because the entire size to be scanned is considered, we make an accurate determination of smart scan benefits and the risk of cache thrashing.
Serial Scans on partitioned tables do not involved the coordinator and have no opportunity to get the larger picture, instead they start work immediately so each partition is considered one at a time and only that one partition’s size is considered by the decision for using Buffer Cache or Direct Read (and hence offload). In the presence of very large buffer caches any given partition can fail the “Is Medium” test (or even the “Is Small” test) and so not get offloaded.
In order to avoid this situation an upper bound of 100MB for using a buffer cache scan has been implemented for any serially scanned segment that:
- isn’t using Automatic Big Table Caching (ABTC).
- hasn’t had the Small Table parameter changed to a non-default value.
Any partitions larger than 100 MB will now automatically use Direct Read and hence offload on Exadata.
See also: Part 1
See also: Part 2
NSMTIO: kxfxghwm:[HWM_NOT_FOUND]
Another case to watch out for is when NSMTIO tracing shows HWM_NOT_FOUND and then choosing a Buffer Cache scan when a Direct Read offloaded scan would have been faster. This can happen when a PQ query gets executed serially (NB: this is NOT the downgrade to serial case, this is still PQ but on a single thread). In this case the coordinator again does not have the opportunity to process all the partitions and as part of that gather the High Water Mark (HWM) for each segment and checkpoint them so we fall back on buffer cache scans. A fix for this is currently being investigated.
Mixed Block Sizes
I have consistently advised against mixing block sizes in a database without a compelling reason backed up by empirical evidence, but for those who must the “Is Medium Table” logic for whether to use buffer cache or direct read has been improved when the database has more than one block size in use. This is tracked by bug 24655250 and fixed in 20.1.
See also Random thoughts on block sizes
Simple function returning Parallel slave info
You can add also any information from v$rtsm_sql_plan_monitor if needed
create or replace function px_session_info return varchar2 parallel_enable as
vSID int;
res varchar2(30);
begin
vSID:=userenv('sid');
select
to_char(s.server_group,'fm000')
||'-'||to_char(s.server_set,'fm0000')
||'-'||to_char(s.server#,'fm0000')
||'('||s.sid||','||s.degree||'/'||s.req_degree||')'
into res
from v$px_session s
where s.sid=vSID;
return res;
exception when no_data_found then
return 'no_parallel';
end;
/
Simple example:
select--+ parallel
px_session_info, count(*)
from sys.obj$
group by px_session_info
/
PX_SESSION_INFO COUNT(*)
------------------------ --------
001-0002-0001(630,2/2) 38298
001-0002-0002(743,2/2) 34706
Smart Scan and Recursive queries
Since Christmas I have been asked to investigate two different “failures to use Smart Scan”. It turns out they both fell into the same little known restriction on the use of Direct Read. Smart Scan critically depends on Direct Read in order to read the synthetic output blocks into private buffers in PGA so with Direct Read disabled Smart Scan is also disabled. In these two cases the restriction is on using Direct Read on Serial Recursive queries.
Case 1: Materialized View Refresh
A customer asked me to investigate why his MView refresh was running slowly and was failing to use Smart Scan. He had used 'trace[NSMTIO] disk=highest' which showed the cause as:
Direct Read for serial qry: disabled(::recursive_call::kctfsage:::)