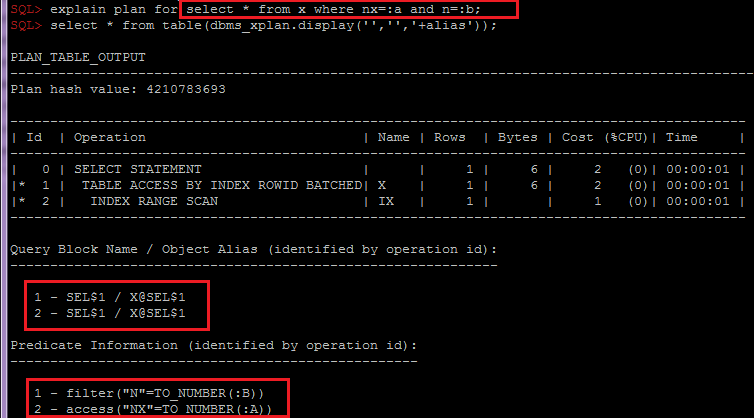
You can add also any information from v$rtsm_sql_plan_monitor if needed
create or replace function px_session_info return varchar2 parallel_enable as
vSID int;
res varchar2(30);
begin
vSID:=userenv('sid');
select
to_char(s.server_group,'fm000')
||'-'||to_char(s.server_set,'fm0000')
||'-'||to_char(s.server#,'fm0000')
||'('||s.sid||','||s.degree||'/'||s.req_degree||')'
into res
from v$px_session s
where s.sid=vSID;
return res;
exception when no_data_found then
return 'no_parallel';
end;
/
Simple example:
select--+ parallel
px_session_info, count(*)
from sys.obj$
group by px_session_info
/
PX_SESSION_INFO COUNT(*)
------------------------ --------
001-0002-0001(630,2/2) 38298
001-0002-0002(743,2/2) 34706